Cyrille Courtière Fondateur Klaxit
Cool IT nous a accompagné dans le pilotage d’un projet très ambitieux de MaaS pour Nantes Métropole. Dans un contexte complexe, avec de nombreuses parties prenantes et un risque projet élevé, il a su rapidement prendre ses marques pour nous aider à structurer et fluidifier la relation avec le client. Je recommande Cool IT pour son sérieux, son sens de l’écoute et son engagement
Cyrille Courtière • Fondateur Klaxit

Comment utiliser l'IA en réduisant les risques cyber ?
Comme n’importe quelle technologie, entre de mauvaises mains et avec de mauvaises intentions, les technologies de l’IA peuvent tout à fait servir à augmenter et diversifier les cybermenaces.
Bien heureusement, avec une bonne prise de recul, un esprit ouvert et une petite routine de cyber au quotidien, il est tout à fait possible d’expérimenter des « IA »[1] en prenant le moins de risque possible.
[1]On dit « IA » avec des guillemets, car cette appellation reste plus compréhensible, que les abréviations techniques telles que GAN, ANI, AGI, ASI… : https://coolitagency.fr/bien-utiliser-les-differents-termes-de-lintelligence-artificielle/
Sommaire
#1 – Ce qui est nouveau est faillible et instable
#2 – Les typologies de données exploitables
#3 – Les usages malveillants possibles
#4 – Les bonnes pratiques pour utiliser des « IA » en toute cybersécurité
#1 – Ce qui est nouveau est faillible et instable
Une technologie nouvelle, une technologie expérimentale, comporte toujours un ensemble de failles, à la fois technique et fonctionnel. C’est normal d’ailleurs ! A un moment, confronter un prototype au public, contribue à l’améliorer ! Le problème, c’est que ces failles, détectées et décortiquées au bon moment, permettent aux cyberattaquants de préparer des actions et d’anticiper des parades.
On entend par failles techniques, l’ensemble des instabilités communes à des lancements de nouvelles technologies, comme :
- La protection incomplète des accès non-autorisés ;
- La vérification incomplète des entrées de formulaires, des entrées API ;
- La non-unicité des identifiants d’accès ;
- La mauvaise anticipation des surcharges serveurs…
Ces failles techniques sont régulièrement revues et rectifiées au fil des mises à jour. Ce qui est exploité par les cyberattaquants, c’est le laps de temps qu’il faudra aux techs pour identifier les failles et les corriger.
On entend par failles fonctionnelles, l’ensemble des usages négligents que nous pouvons avoir, en tant qu’internaute, à la sortie d’une nouvelle technologie :
- Ne pas se renseigner sur l’état d’avancée de la technologie ;
- Ne pas se renseigner sur l’exploitation de nos données ;
- Dissocier la technologie de ses enjeux sociaux, économiques et juridiques ;
- Charger des données personnelles et sensibles (photos, url privé, fichiers d’entreprise, biométrie, localisation, état de santé…) ;
- Ne pas diversifier ses usages, ni ses sources de vérification d’informations…
Nous sommes naturellement négligents, par enthousiasme, parfois par FOMO (Fear of missing out, Peur de rater quelque chose d’incontournable). Malheureusement, les pirates malveillants maîtrisent très bien notre attrait de la nouveauté, pour cartographier les comportements qui facilitent les intrusions, les vols de données.
#2- Savoir ce que les IA exploitent, pour savoir ce qu'on doit protéger
Qu’il s’agisse d’une IA conversationnelle, un assistant de recherche, ou un générateur de contenu, nous sommes susceptibles d’y laisser des données précieuses, en fonction de la base de connaissance de ces « IA » :
- Des données physiques : Visage, voix, biométrie…
- Des données comportementales : Achats, goût, avis, historique de recherche…
- Des données démographiques : Localisation, Genre, Âge…
- Des données sociales : Statut, revenu, orientation politique…
- Des données professionnelles : Compte-rendu, données financières, flux logistiques, état de production, données RH, code informatique sensible…
Comprendre ce que les technologies de l’IA exploitent peut constituer un bon moyen de discerner ce qu’on peut, ou non saisir comme données, ainsi que le niveau d’anonymisation qu’on doit apporter.
#3 – Les usages malveillants possibles
L’attaque par Prompt Injection
- Le périmètre : Les IA conversationnelles et les IA génératives
- Le principe : Injecter des requêtes (appelées Prompt), qui à force de répétition, vont pousser l’IA à passer au-delà des restrictions de sa programmation d’origine
- La faille : La nature des IA, conçues pour apporter une réponse satisfaisante, mais pas forcément fiable, morale ou légale
- L’objectif : Pousser l’IA à partager des informations illicites, ou réaliser des actions illicites
L’industrialisation du phishing
- Le périmètre : Les IA génératives
- Le principe : A partir d’un objectif d’attaque, détourner l’IA pour qu’elle génère des modèles d’arnaque en fonction d’un ciblage
- La faille : Les IA ne peuvent pas évaluer l’intention de leurs usagers. Si je demande de générer un modèle d’e-mail à la manière d’une banque, l’IA ne peut pas deviner que l’e-mail va servir à du phishing bancaire.
- L’objectif : Réduire le temps de création de contenu destiné au phishing
La propagation de faille de code
- Le périmètre : Les générateurs de code
- Le principe : Injecter du code malveillant, ou erroné
- La faille : Le copier-coller sans revue de code et le manque de modération des générateurs
- L’objectif : Propager des malwares, des accès non-autorisés, faire planter un système, et ce, sans qu’on puisse facilement remonter vers la personne à l’origine du code
L’usurpation
- Le périmètre : Les générateurs d’images et les deep technologies
- Le principe : Récupérer des traits physiques, des voix, des mouvements
- La faille : L’opacité des politiques de confidentialité, les effets de mode qui nous poussent à nous jeter sur le dernier filtre amusant, sans se poser de questions
- L’objectif : Recréer des images factices (des photos, comme des vidéos) à des fins d’extorsion
Les crimes pornographiques
- Le périmètre : Les générateurs d’images et les deep technologies
- Le principe : Similaire à l’usurpation, il s’agit aussi de récupérer des éléments physiques, sans le consentement des usagers
- La faille : La mise en public de nos visages sur les médias sociaux
- L’objectif : Recréer des images pornographiques, sans le consentement des personnes dont on exploite l’image, à des fins d’extorsions, des fins criminelles, de commerces illicites
Le vol de données
- Le périmètre : Les IA conversationnelles et les IA génératives
- Le principe : Créer des contrefaçons d’application, en faisant passer le service pour une alternative gratuite, ou peu chère
- La faille : Le manque de modération des fournisseurs d’accès, le manque de vérification des usagers
- L’objectif : Récupérer les données personnelles à des fins d’usurpation, de commerces illicites, ou d’intrusion
La désinformation amplifiée
- Le périmètre : Les IA conversationnelles et les IA génératives
- Le principe : Créer des fakes news et les rendre virales sur un maximum de médias sociaux
- La faille : Le manque de modération, et le manque de modérateurices, la radicalisation des opinions en ligne
- L’objectif : Diffuser du contenu de propagande, déstabiliser des pays, déstabiliser des personnalités publiques et/ou politiques
#4 – Les bonnes pratiques pour utiliser des « IA » en toute cybersécurité
Essayer de prendre connaissance des politiques de confidentialité
Sans forcément en lire l’intégralité, si vous vous rendez compte que les politiques sont absentes, difficiles d’accès, ou incompréhensibles, c’est que le service est potentiellement opaque, et présente un risque pour vos données.
Raisonner le partage d’image personnelles et intimes
Souvenez-vous…50% des contenus pédocriminels ont été créés à partir d’images volées sur les comptes sociaux de l’entourage des victimes. Il en va de même pour les deep fake à usage illicite.
Anonymiser un maximum les fichiers qu’on uploade
Cette présentation que vous voulez rendre plus jolie grâce à PIMP TA PREZ, l’IA qui transforme tes PPT en œuvre d’art, comporte-t-elle des données confidentielles ? Votre entreprise vous autorise-t-elle à utiliser ce type de service ? Que peut-il se passer si ces données sont exploitées par des tiers ?
Donner des feedbacks
Les contenus générés par les « IA » du moment, sont tirés de ce qui est le plus viral, le plus populaire, et le plus requêté, in-app (depuis le service), ou plus globalement sur Internet.
Si un contenu que vous avez fait générer vous met mal à l’aise, vous paraît biaisé, ou faux, il faut le signaler. Vous contribuez ainsi à l’éducation de l’IA.
Garder de l’esprit critique
Le contenu que j’ai généré est-il fiable ? Ses informations vérifiables ? Mes sources d’information sont-elles diverses ? Le contenu rassemble-t-il des faits ? Ou des opinions ? Le contenu est-il authentique ? Libre de droit ? Avec l’accord de ses créateurices ?
Déconstruire ses biais de confirmation
L’information que je lis, que je vois, est-elle vraie ? Est-elle factuelle ? Ou est-ce que je la crois vraie, parce qu’elle conforte mon opinion ? Est-ce que des personnes peuvent être lésées si je la diffuse ? Est-ce que je contribue à une diffamation si je la diffuse ?
Avoir une routine de sécurité
Changer régulièrement mes mots de passe, mettre à jour mes applications, rester à l’écoute des alertes au phishing…
Différencier moyen et solution
Les « IA » sont des outils, et ne constituent en rien des « solutions magiques » à des sujets de fond. Si on a une organisation bancale, utiliser une « IA », ou une solution d’automatisation, sans questionner l’organisation, ne fera qu’automatiser, ou répliquer une organisation bancale.
Faire preuve de patience
Les technologies sont mouvantes, et ne cessent d’évoluer, de s’améliorer. Ce qui est faillible aujourd’hui ne le restera pas éternellement. Les usages aussi évoluent. Et les « IA » deviendront ce que nous en ferons…de bien et d’éthique.
Pour aller plus loin
- Le Monde informatique : https://www.lemondeinformatique.fr/actualites/lire-des-failles-critiques-dans-torchserve-fragilisent-des-milliers-de-modeles-d-ia-91766.html
- HTTPCS : https://blog.httpcs.com/une-faille-de-securite-par-prompt-infection-touche-les-ia-generatives-comme-chatgpt-et-google-bard/
- NUMERAMA :
- https://www.numerama.com/cyberguerre/1554992-chatgpt-est-en-panne-des-hackers-pro-russes-revendiquent-la-cyberattaque.html
- https://www.numerama.com/tech/1542866-lia-deshabille-des-photos-denfant-pour-en-faire-de-la-pedopornographie.html
- https://www.numerama.com/tech/1542498-phishing-chatgpt-fait-presque-aussi-bien-que-les-pirates-et-cest-un-probleme.html
- WASHINGTON POST : https://www.washingtonpost.com/technology/2023/11/05/ai-deepfake-porn-teens-women-impact/?utm_campaign=%23R%C3%A8gle30%20165&utm_medium=email&utm_source=newsletter_edito
- NEXT INPACT : https://www.nextinpact.com/article/71011/dangers-grands-modeles-langage-chercheuses-avaient-prevenu
- « L’intelligence artificielle n’existe pas », Luc Julia, éd. First
- « Ce sera l’IA oui/et moi », Cécile Dejoux, éd. Vuibert
- « Résistance 2050 », Aurélie Jean et Amanda Sthers, éd. L’observatoire
- Le DAIR Institute, https://www.dair-institute.org/research/
- « Technoféminisme, comment le numérique aggrave les inégalités », Mathilde Saliou éd. Grasset : https://www.nextinpact.com/article/71410/en-ligne-misogynie-utilisee-pour-saper-liberte-dexpression
- Rapport de l’Unesco, sur l’éthique des Intelligences Artificielle, datant de 2021 : https://unesdoc.unesco.org/ark:/48223/pf0000381137

Bien utiliser les différents termes de l'Intelligence Artificielle
Il faut qu’on vous avoue quelque chose…C’est très difficile à exprimer, alors nous irons droit au but ! L’Intelligence Artificielle ne sert pas à travailler, ni à prendre des décisions à votre place !
Pourquoi ? Parce que c’est tout simplement irréalisable pour l’instant. Les recherches autour des Intelligences Artificielles avancent d’année en année. Nous découvrons des programmes très impressionnants tels que ChatGPT, Lensa ou Dall•E, qui annoncent, pour le futur, de nouvelles opportunités de support au travail des Humains. Mais ce n’est pas une raison pour dire n’importe quoi sur les IA, et ce pour plusieurs raisons :
– Pour ne pas se fier à 100% aux contenus des IA, sans vérification ;
– Pour ne pas décevoir les utilisateurs ;
– Pour ne pas décevoir des investisseurs potentiels ;
– Pour ne pas limiter les IA à un sujet informatique ;
– Pour recruter des personnes qualifiées etc.
Vous l’aurez compris, plus vous utiliserez correctement les termes et le vocabulaire de l’Intelligence Artificielle, plus vous serez à même de ne pas vous faire avoir, ou de générer trop d’attente autour d’un projet d’IA.
On vous explique ?
#1 — Il n’y a pas une, mais DES Intelligences Artificielles
Au sens stricte, l’Intelligence Artificielle est un ensemble de théories, techniques et disciplines, dont l’objectif est de doter la machine d’une simulation d’intelligence humaine, sur plusieurs périmètres :
- L’apprentissage ;
- La communication ;
- L'aide à la décision ;
- La résolution de problème ;
- La création ;
- La fabrication ;
- La prédiction...
- Ressentir
- Construire une opinion
- Exprimer des émotions
- S’adapter
- Tirer des leçons personnelles…
Au même titre qu’il n’y a pas un seul modèle d’intelligence chez l’Humain, il y a plusieurs modèles d’Intelligence Artificielle :
L’IA faible ou étroite – ANI
- Il s’agit des IA mises en œuvre aujourd’hui sur différents services : chatbot, moteur de recherche, outil de ciblage, reconnaissance faciale, reconnaissance vocale.
- Elles sont dites « faibles » car elles sont configurées en amont pour imiter une action unique, de manière automatique, à partir de bases de connaissance définies et encadrées.
- Elles ne sont pas pleinement autonomes, et nécessitent des vérifications.
L’IA forte ou générale – AGI
- Ce type d’IA n’est aujourd’hui qu’au stade du concept et de l’expérimentation.
- Pour passer d’une IA faible à une IA forte, il faudrait qu’elle soit en mesure de s’adapter à l’imprévu, apprendre d’elle-même, raisonner et comprendre « exactement » comme un humain, pour résoudre des problèmes, et réagir à des situations.
La super intelligence – ASI
- C’est l’IA de science-fiction, à savoir une IA qui agirait exactement comme l’Humain
- C’est l’IA qui aurait son individualité, et sa conscience propre, quitte à surpasser l’Humain, grâce à des capacités d’analyse et de ressenti qui lui seraient propre
Où est-ce qu’on veut en venir ?
- Il faut être vigilant dans la manière de présenter un projet d’IA, afin de ne pas décevoir l’utilisateur…ou des financeurs, avec une solution miracle
- On ne peut pas réduire l’IA à une discipline purement informatique et technique
- L’activité d’une IA doit toujours être supervisé et vérifié
Exemple d’abus
de langage
- Sens n°1 / Catégorie Abus Gentil : Notre entreprise investit dans l’automatisation pour faciliter certaines tâches
- Sens n°2 / Catégorie Abus Abusé : Notre entreprise n’investit dans rien du tout, mais parler d’IA c’est bon pour l’image
- Sens n°1 / Catégorie Abus Gentil : Notre CRM segmente bien vos fichiers clients, suggère des actions, automatise les envois d’e-mail
- Sens n°2 / Catégorie Abus Abusé : Les commerciaux ne connaissent pas bien le produit, mais maîtrisent les mots à la mode
- Sens n°1 / Catégorie Abus Gentil : Notre solution facilite la prise de décision, en organisant bien les données
- Sens n°2 / Catégorie Abus Abusé : Nous utilisons des anglicismes à la mode, pour vendre une solution qui fait de jolis tableaux de bords
#2 – Les notions à ne pas confondre
IA et Machine Learning
Le Machine Learning est un modèle d’apprentissage pour les IA. À partir d’un ensemble de données, d’algorithmes et de modèles mathématiques, le Machine Learning permet à un système informatique de réaliser des actions, sans être directement dirigé par l’Humain.

Le Machine Learning est exploité dans plusieurs champs d’application comme la reconnaissance vocale (Siri, Alexa), la vision par ordinateur (analyse d’images), la prédiction de résultats, la compréhension de langage naturel (chatbot), reconnaissance d’image (recherche inversée), le transport autonome, la recommandation, le ciblage publicitaire…
IA et Deep Learning
Le Deep Learning est un autre modèle d’apprentissage pour les IA. Ce modèle vise à intégrer des réseaux de neurones dits « profonds » pour permettre aux IA d’analyser des données, de manière plus subtile.
Contrairement au Machine Learning qui traite la donnée de manière linéaire, le Deep Learning apprend aux IA à traiter les données par couche, de plus évident au plus abstrait, comme un arbre de décision géant. On l’exploite aujourd’hui pour la reconnaissance d’image, la reconnaissance vocale, la compréhension de langage naturel, la génération de contenu, la traduction, la détection de fraude…

IA et Algorithme
En informatique, un algorithme est une suite d’étape que l’on rédige, qu’on modélise, à partir de différentes informations, pour qu’un système informatique génère des résultats ou des actions.
Les algorithmes ne sont pas des IA, mais une partie de ce qui les fait fonctionner.
IA et Automatisation
L’automatisation n’est pas qu’un procédé informatique, on peut automatiser des choses de manière mécanique, en faisant appel à l’électronique, sans utiliser de systèmes informatiques.
- En informatique, l’automatisation consiste à utiliser des algorithmes pour effectuer des tâches sans l’intervention directe de l’Humain. Exemple : l’envoi d’e-mail programmé
- Il n’y a pas systématiquement une IA derrière un système automatisé.
IA et Chatbot
Un chatbot est un programme informatique capable de converser avec l’Humain, en langage plus ou moins naturel. Pour ce type de service aussi, il n’y a pas systématiquement une IA derrière.
- Les chatbots, sans IA, fonctionnent plutôt comme une F.A.Q dynamique, avec des questions et des réponses pré-enregistrées, à partir de mots-clés.
- Les chatbots, qui intègrent une IA, analyse le langage, apprennent au fur et mesure des échanges, et sont en capacité d’affiner leur réponse.
- Les faux chatbots vous font échanger avec des Humains. Ceux sont des chats quoi !

Médiatisation des cyberattaques : quelle influence sur les habitudes des e-consommateurs ?
À l’heure où l’on médiatise de plus en plus les incidents de sécurité et les alertes de cyberattaque (phishing, malware…), on est venu à se demander si cela venait à influer sur les habitudes de navigation des internautes, initiés ou non à la sécurité :
- Est-ce que cela entraîne de nouveaux usages ?
- Quels effets sur la navigation ? Quels effets sur l’achat en ligne ?
- De quels critères faut-il tenir compte pour rassurer ?
Pour répondre à ces interrogations, nous avons réalisé une enquête en ligne, diffusée sur Instagram, LinkedIn, et directement à notre réseau réparti entre l’Île-de-France, la Bretagne et la Nouvelle Aquitaine. L’objectif étant de rassembler des profils de personne, de la plus experte en cybersécurité, jusqu’à la personne le moins à l’aise avec ce sujet. Nous avons récolté 199 réponses.
#1 — L’âge n’a pas d’influence sur les niveaux de connaissance
Ce qui a le plus d’effet sur ces appétences sont le milieu professionnel, celui de l’entourage ainsi que de mauvaises expériences (arnaque, défiance…)
Cette tendance nous a permis de répartir les répondants en 3 catégories :
- Les cyber-experts (33%), personnes qui maîtrisent la majorité des enjeux de la cybersécurité du quotidien ;
- Les cyber-sophomores (47%), personnes qui appliquent des pratiques de sécurité, sans être des experts ;
- Les cyber-newbies (20%), personnes qui reconnaissent manquer de bonnes pratiques.
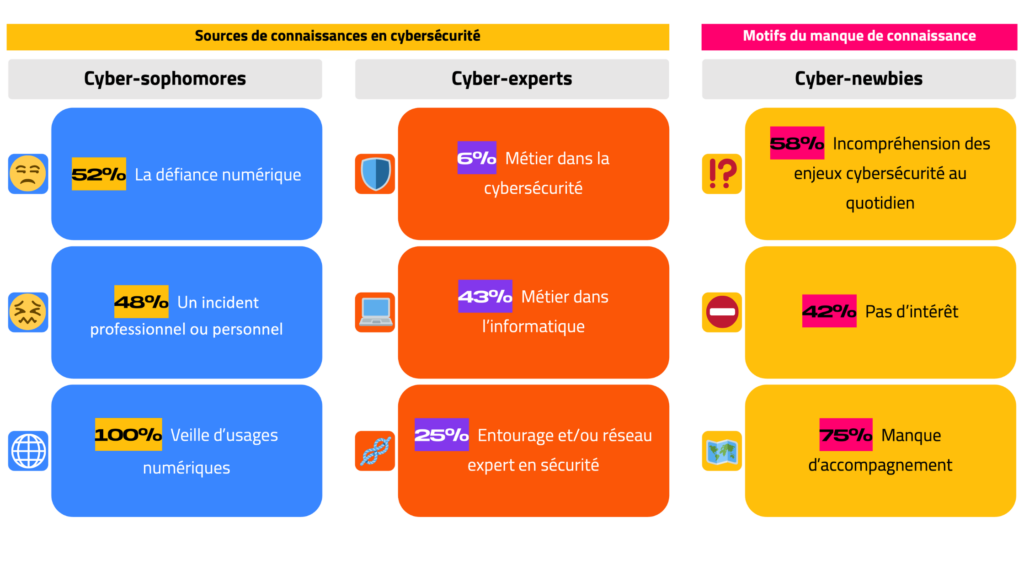
Sources de connaissances
des cyber-experts :
- 6% exercent un métier dans la cybersécurité ;
- 43% exercent un métier dans l’informatique ;
- 25% bénéficient d’un entourage et/ou d’un réseau qui les sensibilise régulièrement.
Sources de connaissances
des cyber-newbies :
- 58% ont du mal à comprendre les enjeux de la cybersécurité au quotidien ;
- 42% ne s’y intéressent pas ;
- 75% considèrent qu’iels manquent d’accompagnement.
Sources de connaissances
des cyber-sophomores :
- 52% ont acquis des connaissances en cybersécurité du quotidien, motivés par leur défiance numérique ;
- 48% ont acquis des compétences, à la suite d’un incident professionnel ou personnel ;
- 100% ont cherché des réponses et des solutions, en mettant en place des rituels de veille d’usages numériques.
La majorité des cyber-experts tirent leurs connaissances soit de leur milieu professionnel, soit celui de leur entourage. Pour les cyber-sophomores, il y a 2 tendances : une défiance pour le numérique, qui poussent à être naturellement vigilant, ou l’assimilation de nouveaux réflexes à la suite d’un cyber-incident. Concernant les cyber-newbies, les trois-quarts estiment que leur manque de connaissance, viennent d’un manque d’accompagnement.
#2 – Rituels de protection
La gestion et la protection des mots de passe sont les actions les plus courantes.
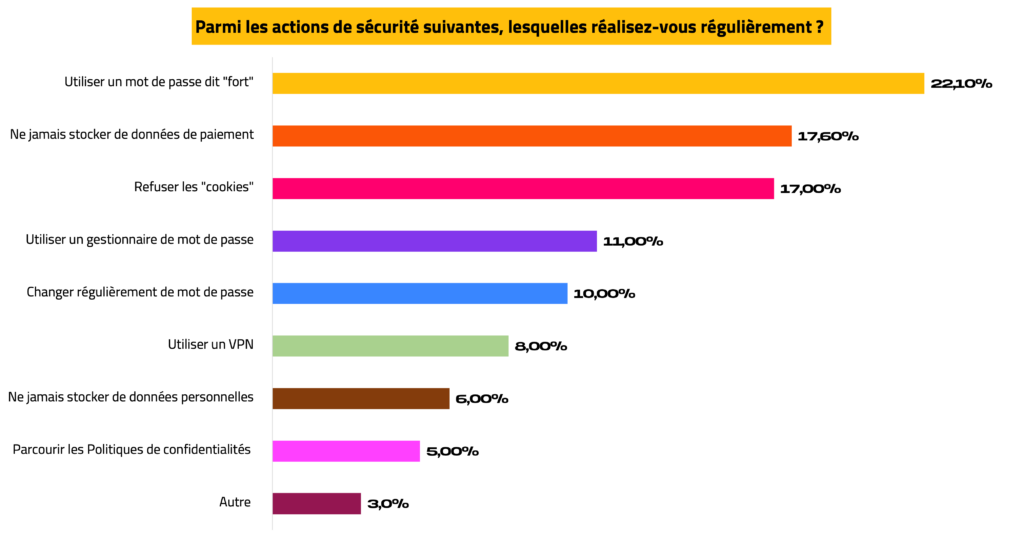
Les répondants qui ont sélectionné « Autre », ont complété leur sélection par les actions suivantes :
- Mise à jour régulière ;
- Privilégier le SSL ;
- Mettre en place une double-authentification ;
- Utiliser un e-mail dédié pour les achats ;
- Utiliser un service tiers de paiement : Paypal, Revolut, Lydia…
#3 – Sentiment de protection, fiabilité du paiement et désengagement
Pour la quasi-moitié des répondants (47%), les Politiques de confidentialité sont contraignantes à lire, à cause de la longueur des textes, qui décourage la lecture. Pour d’autres (41%), c’est davantage le jargon technique et les tournures à interpréter, qui découragent. Cependant, consulter la Politique de confidentialité reste une pratique assez courante quand il y a une mise en doute d’un service (39%).
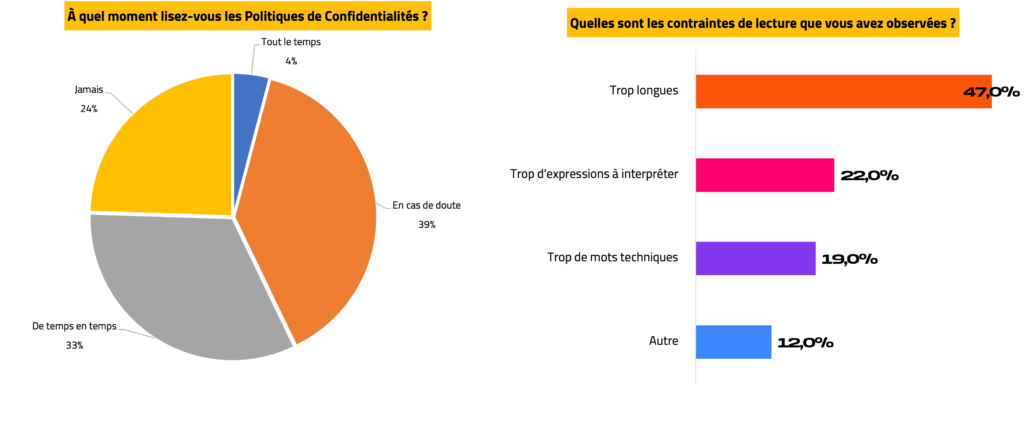
Parmi les répondants qui ont choisi « Autre » (12%), il a été précisé les contraintes suivantes :
- Fait pour ne pas être lu ;
- Ne précise pas le traitement des données par des tiers ;
- Pas adapté au « commun des mortels » ;
- Sensation de ne pas avoir le choix.
Plusieurs questions concernant le respect du RGPD ont été également posées, afin de comprendre l’effet du RGPD sur les usages des répondants. La majorité d’entre elleux (81,6%) considèrent les services qu’iels utilisent, comme flous à ce sujet. Pourtant le respect du RGPD est bien un moteur d’adhésion et d’engagement (80%). En effet, la moitié des répondants (59%) a déclaré s’être déjà désengagée de services, qui semblaient ne pas protéger correctement les données personnelles.
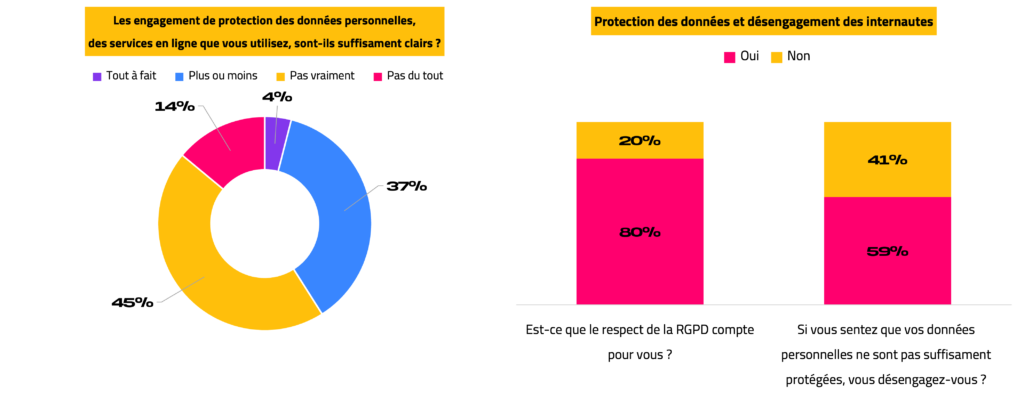 Enfin la fiabilité et l’apparence de l’étape de paiement joue un rôle dans le processus d’achat. Une interface qui ne paraît pas sûre conduit à l’abandon du panier (69%), ou à une suspension de l’achat pour aller récolter des avis sur le Vendeur (24%).
Enfin la fiabilité et l’apparence de l’étape de paiement joue un rôle dans le processus d’achat. Une interface qui ne paraît pas sûre conduit à l’abandon du panier (69%), ou à une suspension de l’achat pour aller récolter des avis sur le Vendeur (24%).
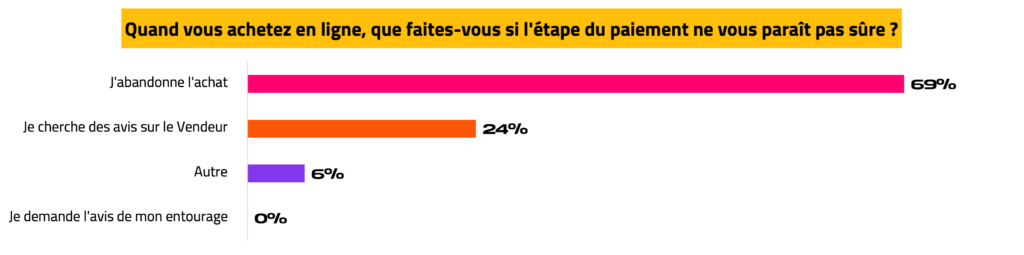
La défiance des internautes envers un service en ligne n’est pas systématique, elle est généralement motivée par :
- La clarté des politiques de protection de la donnée ;
- La traçabilité des données personnelles ;
- La fiabilité du parcours de paiement ;
- L’aspect de l’interface de paiement ;
- La fiabilité du Vendeur, validée par des avis.
Quant au désengagement (résiliation, abandon du panier…) il n’intervient qu’en l’absence d’informations sur un Vendeur, qu’en cas de manquement aux règlementations, ou l’absence de marqueur de fiabilité des interfaces de paiements.
#4 – Avis, fiabilité et bouche-à-oreille
Pour plus de la moitié des répondants (61%), vérifier la fiabilité d’un site dépend de l’objectif principal de la visite : rechercher ou acheter.
Si l’internaute est seulement en recherche d’informations, le site n’est vérifié qu’en cas de doute. En revanche, si l’objectif est d’acheter, vérifier la fiabilité du Vendeur (ou du site marchand) est systématique.
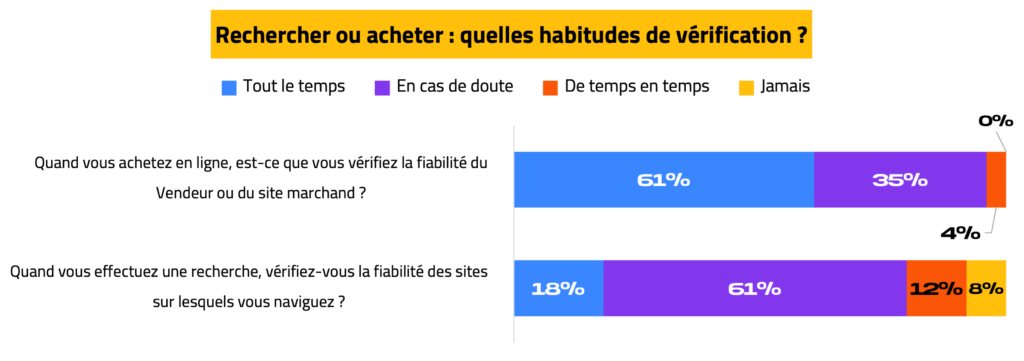
Concernant les sources de vérification, les informations qui permettent d’identifier l’entreprise ou le Vendeur sont plus souvent recueillies (42%), que l’avis de l’entourage (7%).
Quant à l’entourage, ses alertes font l’objet de vérification préalable (73%), avant d’éventuellement se désengager (24%).
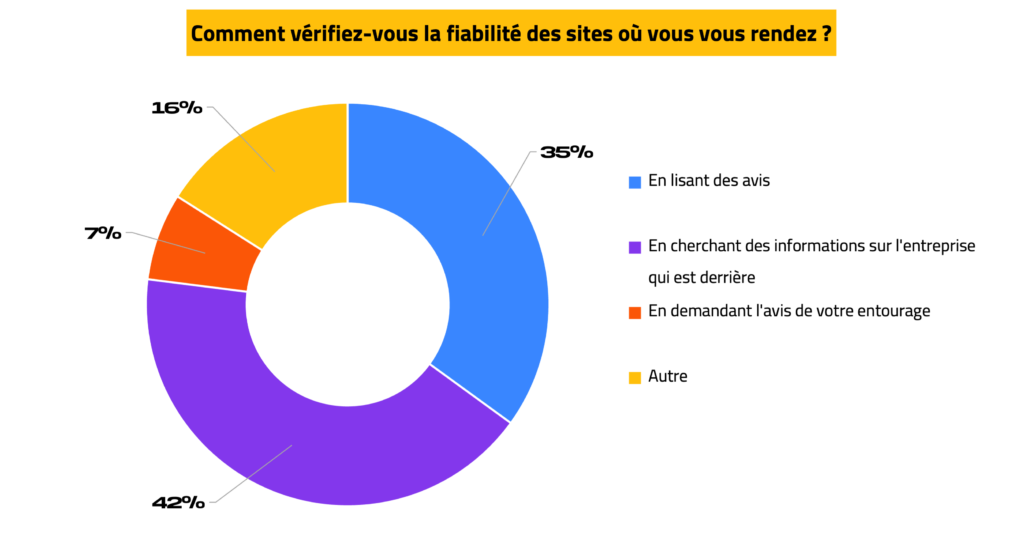
L’existence d’informations, sur la structure propriétaire d’un site (nom de l’entreprise, immatriculation, marque, équipe), semble être un critère plus rassurant, que les avis en ligne, ou les alertes de l’entourage.
L’action de vérification varie en fonction de l’objectif de navigation :
- Si l’internaute cherche à récolter des informations, la vérification n’intervient qu’en cas de doute ;
- Si l’internaute cherche à acheter un produit ou un service, la vérification est systématique avant l’achat.
À propos de la notion « en cas de doute », il y a plusieurs critères :
- L’esthétique du site ;
- La clarté des conditions générales de vente ;
- La traçabilité des produits ;
- Le langage employé ;
- L’absence d’avis ;
- L’absence d’une équipe humaine ;
- L’absence de structure claire (entreprise, marque, ambassadeur…).
#5 – Effets de la médiatisation d’un cyber-incident
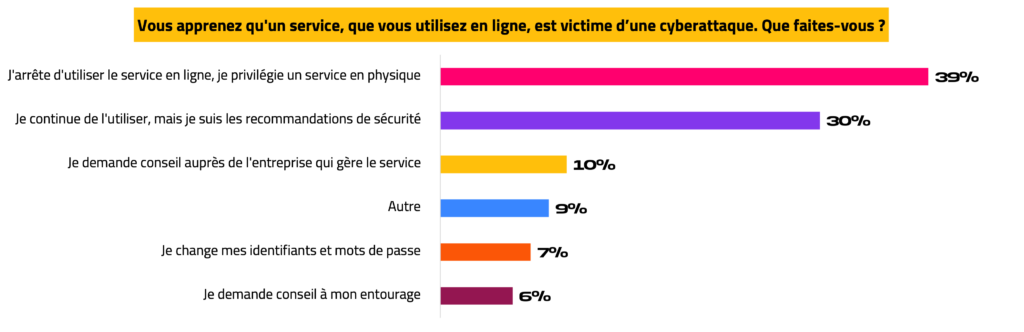
Les répondants, ayant choisi « Autre », ont ajouté les réactions suivantes :
- Vérifier si l’incident n’a pas eu de répercussion sur d’autres services ;
- Attendre de voir des effets concrets avant de réagir.
La divulgation d’un cyber-incident n’est pas source de désengagement, mais de changement de canal d’accès. De plus, certains internautes s’en remettent à l’entreprise compromise, afin de connaître ses préconisations de réaction.
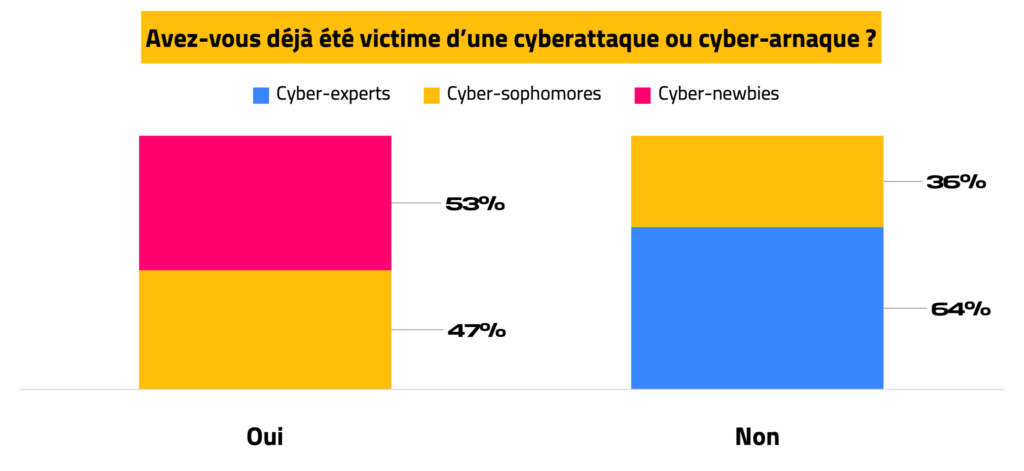
#6 — Les victimes de cyberattaque et/ou arnaque réagissent en misant sur la communication
Parmi les répondants, 14% ont déjà été victime d’une cyberattaque ou d’une arnaque, et sont répartis entre les catégories cyber-newbies (53%) et cyber-sophomores (47%). Les répondants qui n’en ont jamais été victimes (86%), sont répartis entre les catégories cyber-experts (64%) et cyber-sophomores (36%).
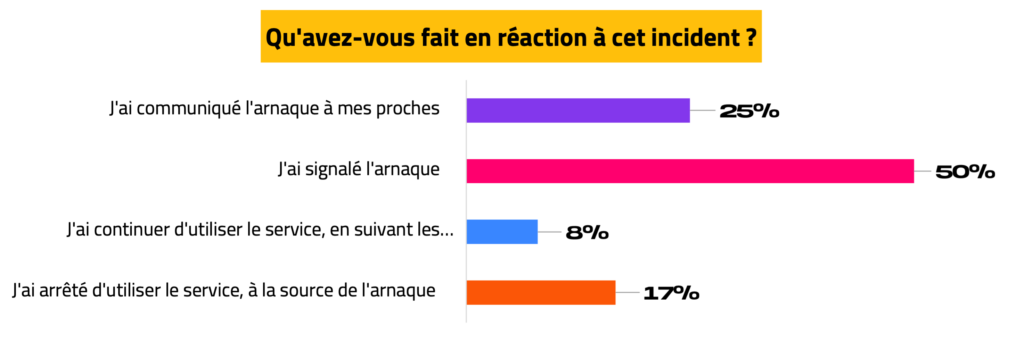
Les personnes ayant été victimes d’arnaque en ligne, ou de cyberattaque, privilégient le signalement de l’incident, avant de tabler sur un arrêt de l’utilisation.
Conclusion ? Reprenons les questions qui nous ont poussé à réaliser cette enquête en ligne :
#1 — Est-ce que la médiatisation plus fréquente des cyberattaques a entraîné de nouveaux usages ?
Il n’y a pas forcément de nouveaux usages, mais une prise de conscience, qui entraîne le renforcement de :
- Pratiques de prévention : Renforcement des mots de passe et renforcement d’actions de vérification (profil vendeur, immatriculation d’une entreprise, existence d’une équipe humaine, avis client…) ;
- Pratiques de réactions : Mise à jour des identifiants, signalement, communication, veille de bonnes pratiques.
#2 — Quels effets sur la navigation ? Quels effets sur l’achat en ligne ?
Le désengagement n’est pas systématique, en cas de ressenti d’insécurité en ligne. Tout dépend de l’objectif de l’internaute :
- S’il s’agit de réaliser une recherche, lire, se divertir, il n’y aura désengagement qu’après vérification de plusieurs informations sur le gestionnaire du site. Cette vérification n’entre en vigueur, qu’en cas de doute ;
- S’il s’agit d’acheter un produit ou un service, la vérification est systématique avant l’achat. Le désengagement opère majoritairement quand le parcours de paiement paraît long, ou peu fiable.
À la suite d’un incident, le désengagement n’est pas systématique non plus. La réaction des internautes varie en fonction :
- De la nature de l’incident : Arnaque, spam, phishing, malware…
- De l’effet de l’incident sur d’autres services
- De la réaction de l’entreprise gestionnaire du service en ligne
De plus, si le service en ligne existe en physique, le service physique est privilégié le temps que l’incident soit résolu.
#3 — De quels critères faut-il tenir compte pour rassurer les internautes ?
Les critères qui rassurent peuvent être regroupés en plusieurs catégories :
- L’esthétique et la facilité de navigation — Plus l’accès à une information paraît complexe, plus l’internaute doute de la fiabilité du service. Eh oui…un site « moche », ou qui ne correspond pas à ce qu’on attend d’un service, suscite de la défiance.
- La clarté de l’information — Plus les informations essentielles (sources, prix, conditions de livraison, CGV, CGU…) sont claires et en langage courant, plus les services sont attractifs
- La traçabilité — Les internautes veulent connaître les sources d’une information, la provenance des produits, le rôle des intermédiaires, ce qui est fait des données personnelles…
- L’humanité — On veut vous voir…et savoir qu’il y a une structure existante, des humains, des équipes identifiables, qui travaillent derrière un site