
Who Run The Tech 2024 : Ce que les dev’ de la Cool Team ont appris
En novembre dernier, la Cool Team a empaqueté son goûter et sa trousse de crayons, direction Rennes pour faire le plein d’enseignements auprès des speakeuses de Who Run The Tech. On vous l’avait dit dans notre newsletter (faut la lire, vous ratez un truc), on ne sort pas souvent de nos bureaux, mais quand on le fait, on ne rigole pas avec nos choix d’événement.
Ça fait un moment, mais ce n’est jamais trop tard quand il y a quelque chose à transmettre
Nos développeurs ont ainsi pu tester le degré de leur savoir sur différents domaines allant de la cybersécurité aux pratiques du craft, en passant par des approches de code pure, de conception, d’organisation du travail. Parce que c’est aussi, et surtout ça, le métier de dév, c’est entraîner sa curiosité, cultiver la remise en question de ses acquis, et nourrir ses compétences auprès de ses pairs.
Erwan, Florence et Marie vous proposent un top 5 des conférences auxquelles ils ont pu participer tout au long d’une journée d’événement comptabilisant pas moins d’une trentaine de conférences, quickies et ateliers. On va vous parler des choses qu’on a apprises, celles qui nous ont marquées et ce qu’on compte faire de ces nouveaux savoirs dans notre métier de tous les jours.

On n'a pas pu tout voir, mais on a assisté à tout ça
JAMing with Performance - Alex Palma
Erwan, notre Cool ingénieur, a assisté à la conférence d’Alex Palma, développeuse font-end chez Zenika Brest, portant sur la Jamstack.
De quoi on parle ?
La Jamstack, acronyme de Javascript API Markup, est une approche, une architecture utilisée pour construire des sites web. Elle a été créée en 2015 par Mathias Biilmann, PDG de la firme de cloud computing Netlify.
L’objet de la conférence mettait en lumière l’obsolescence critiquée de cette architecture. Décrite comme « trop vieille » et « plus adaptée » par les développeurs, notamment face aux évolutions du secteur (les sites ultra personnalisés et très dynamiques), ou à l’apparition de frameworks plus modernes comme Next.js, entre autres.
Qu’est-ce qu’on a appris ?
Aujourd’hui, la Jamstack est encore massivement utilisée, sans que cette étiquette soit forcément collée sur ses lignes de code. C’est une pratique qui est entrée dans les fondements du développement front-end, pour en faire complètement partie. Elle permet notamment de travailler sur un front autonome et autosuffisant, permettant de créer des applications réfléchies sous l’angle de l’écoconception.
La désuétude n’est pas une caractéristique de la Jamstack qui reste pertinente pour des projets relativement simples et statiques, comme des sites vitrine, des landing pages, ou la création de blogs. L’approche se révélera moins adaptée pour des projets interactifs, où le dynamique est omniprésent.
Qu’est-ce qu’on va appliquer ?
L’adage « Être statique par défaut et appliquer de la complexité s’il faut » est une pratique intéressante mise en avant par Alex qui propose de profiter de la Jamstack pour ce qu’elle a à offrir d’efficace et de stable, à savoir minimiser les couches successives de dynamismes quand il n’y a pas d’objectif concret.

TDD, décortiqué, pratiqué, démystifié - Jacqueline Rwanyindo
Nos deux développeuses Florence et Marie sont pu participer à l’atelier proposé par Jacqueline Rwanyindo, Ingénieure logiciel, chez Ippon Technologies abordant la pratique du TDD.
De quoi on parle ?
Le TDD est une pratique Craft qui permet de concevoir des logiciels par itérations successives très courtes. Chaque itération est réalisée grâce à la résolution d’un problème dédié, via l’exécution de tests, et la prise en compte de feedback. Le code n’est créé qu’en dernière étape, et a pour vocation d’être le plus simple possible.
L’une des pratiques les plus courantes, et les plus répandues en TDD, est le « Baby Steps », expliqué lors de l’atelier via la réalisation du kata FizzBuzz.
Qu’est-ce qu’on a appris ?
Le kata met en lumière l’importance de la rédaction de tests en amont de la rédaction du code. Prévoir ses tests permet de :
- Alléger la charge mentale
- Organiser son travail
- Gagner du temps pour produire un code de qualité, puisque cette réflexion force les développeur.eures à anticiper les anomalies
Qu’est-ce qu’on va appliquer ?
La rédaction de listes de tests est une pratique que l’on compte appliquer dans nos méthodologies, suivant deux temporalités : en phrase de conception et en phase de développement (production de code).

Améliorer l'implémentation du feature flip pour réussir à avoir du flow - Dorra Bartaguiz
Nous étions plusieurs membres de l’agence à assister à cette conférence, quelque peu intrigués par le titre et encore plus par le contenu. Dorra Bartaguiz, CTO chez Arolla, a magiquement transformé l’utilisation du « feature flip » en une liste de do’s and dont’s, pour finalement ne nous donner qu’une seule et bonne raison d’utiliser cette fonction : éviter de le faire. Malin.
De quoi on parle ?
Le Feature flipping est un mécanisme permettant d’activer, ou désactiver une fonctionnalité directement en production, sans avoir à re-déployer du code.
Qu’est-ce qu’on a appris ?
Le feature flipping s’avère parfois problématique. On le déploie pour contrer les conséquences d’un code mal conçu, pour activer/désactiver un bout code non terminé, ou activer/désactiver une fonctionnalité qui vient d’être livrée, mais qui ne correspondrait pas à la demande du client.
Dorra Bartaguiz a créé cette conférence dans le but de désamorcer la mauvaise utilisation du feature flip, mais aussi et surtout, d’améliorer son utilisation chez les dévs.
Elle a présenté différentes méthodes de mise en action du feature flip, qui sont courantes, et plus ou moins saines comme :
- Trunk base developpement : Travailler sur le tronc commun du code, pas de branches
- Branch base development : Utiliser une seule feature par branche, avec un merge en fin de développement
- Livraison partielle : Éviter l’effet tunnel pour réduire le cycle de vie des branches
- Activation selon contexte : Activer/désactiver selon des situations, des déclencheurs précis
- Dépendance externe : Activer/désactiver des fonctions selon les usages des utilisateurs finaux
Pour ne pas succomber à la solution de facilité, Dorra propose une alternative sécuritaire et pérenne : le Circuit breaker.

Qu’est-ce qu’on va appliquer ?
Même si, de base, la technique du feature flip est peu utilisée dans les principes de développement de nos Cool Devs, elle reste une méthode intéressante de part ce qu’elle révèle. Elle appuie l’importance de réfléchir avant de coder. Réfléchir sa conception est essentiel pour éviter l’abus du feature flip, qui en plus de rendre impossible la maintenance d’une application, ne permet pas de créer du code simple et clair.
La réflexion de la conception passe par le découpage des tâches en amont, l’implication du Métier et des Utilisateurs finaux, méthodo déjà largement inscrite dans nos principes de dev, mais qu’on peut étoffer grâce au mind mapping.

Décodons nos pipelines : Comprendre pour mieux déployer - Hafsa Elmaizi
Nos trois développeurs ont assisté à la conférence de Hafsa Elmaizi, Développeuse Back-End chez SII, pour tenter d’en apprendre plus au sujet des pipelines CI/CD.
De quoi on parle ?
Un pipeline est une série d’étapes à suivre lorsqu’on déploie du code, qui permet de vérifier la qualité du code, sa sécurité et sa fiabilité. Les pipelines permettent également de déployer automatiquement le code sur un serveur.
Qu’est-ce qu’on a appris ?
Comprendre ses pipelines, c’est cool ! Savoir écrire ses pipelines, c’est encore plus cool ! Généralement pris en charge par les DevOps, la configuration de pipeline par les développeur.euses comporte de nombreux avantages :
-
- Responsabilisation des équipes de développement sur le déploiement
- Alignement des équipes de dev et devOps
- Détection et résolution rapide d’erreurs de déploiement
- Optimisation sur la qualité de code
- Anticipation et adaptabilité en cas d’incident et autres
Grâce à cette compétence, on peut facilement :
-
- Lancer des tests unitaires & d’intégration
- Réaliser des tests de charge
- Tester différents niveaux de sécurité (code, dépendance, etc.)
- S’assurer des livraisons continues vérifiées
Qu’est-ce qu’on va appliquer ?
Des templates de configuration de pipelines existent et ils pourraient se révéler intéressants à étudier, dans le cadre de nos projets futurs.

Représentation des scénarios d'attaques avancées - Valérie Viet Triem Tong
Notre développeuse-to-be Marie a assisté à la conférence de Valérie Viet Triem Tong, Professeure en Cybersécurité à la CentraleSupelec, et chercheuse, sur les scénarii plus ou moins longs d’attaques sur des systèmes d’information.
De quoi on parle ?
Valérie Viet Triem Tong propose de plonger avec elle dans son sujet d’étude de prédilection, sujet auquel elle a déjà dédié 10 ans de sa carrière, les APT.
APT signifie « Advanced Persistent Threats », et désigne un attaquant avec un objectif, qui va prendre le temps nécessaire, parfois des années, pour s’infiltrer dans un SI. Les APT sont les attaques les plus difficiles à reconnaître et à anticiper. Ce type d’attaque étant très peu documentée du fait du protectionnisme des entreprises sur cette typologie de crise interne.
Qu’est-ce qu’on a appris ?
Malgré le manque de ressources et de data, un Cyber Kill Chain est créé en 2011, permettant d’identifier plusieurs étapes dans les attaques APT :
- Entrée dans le SI par une des nombreuses entrées : à ce stade, l’attaquant ne sait pas vraiment où il se trouve, et doit donc « explorer » autour de lui
- Propagation dans le réseau : prendre le maximum d’informations, jusqu’à trouver le service cible, souvent de manière visible
- Il disparaît, travaille en parallèle pour simuler l’attaque grâce aux infos qu’ils a récupérées. Cette phase d’essai/erreur peut durer des semaines, mois ou années avant de produire une version « finalisée » d’intrusion
- Il revient avec son attaque consolidée
Bien que les premiers modèles apparaissent, le manque de données réelles freine la recherche. En effet, une application attaquée sera très souvent immédiatement, ne permettant pas de garder une photo de l’instant T de l’attaque.
Pour remédier à cette pénurie, Valérie Viet Triem Tong lance un appel aux entreprises favorables à un travail avec son équipe, dans le but de faire avancer les recherches scientifiques pour faire évoluer le modèle, en collaboration avec Pirat/’) ;, son collectif de chercheur.euses.
Qu’est-ce qu’on va appliquer ?
Les conseils simples, mais efficaces, de Valérie sur les réflexes cybers accessibles :
– Changer son mot de passe régulièrement
– Éviter les doublons d’identifiants
– Mettre en place routine régulière de ces changements
Autant de pratiques que l’on souhaite enseigner de manière systématique à nos clients, comme un devoir professionnel, notre serment d’Hippocrate à nous.
EN RÉSUMÉ
Who Run The Tech s’affirme, année après année, comme un événement incontournable dans le paysage de la tech, grâce à la richesse de ses interventions et à sa vision inclusive et engagée. En donnant la parole à des femmes expertes du secteur, cet événement ne se limite pas à transmettre des savoirs : il agit comme un levier de changement, en mettant en lumière les problématiques d’inclusivité et leurs conséquences sur l’innovation. Une initiative inspirante qui, au-delà de rassembler, invite chacun et chacune à repenser le futur de la tech de manière plus juste et équitable.

L'intelligence artificielle : Histoire, Réalités et Fantasmes
L’intelligence artificielle est sur toutes les lèvres. Qu’il s’agisse de prédictions apocalyptiques ou de promesses de révolutions technologiques : l’IA fascine autant qu’elle inquiète. Les spéculations sur ces IA super-intelligentes, autonomes et capables de remplacer l’Humain sont au cœur de tous les talk-show, de tous les argumentaires journalistiques, de tous les débats en repas de famille.
On nous demande souvent de prendre position sur le sujet d’ailleurs, et on admet que l’exercice n’est pas facile pour nous. Vous commencez à nous connaître, chez Cool IT, c’est toujours « ni oui ni non ». On en a déjà parlé sous le prisme de la cybersécurité et de la vulgarisation de jargon.
Cependant, il semblerait que vous attendiez plus de ressources de notre part pour rassurer tonton José persuadé que « L’IA va nous détruire », ou contenir Sadia du marketing convaincu que « Si on s’y met pas, on est mort ! », sans trop savoir ce que votre entreprise pourrait faire avec.
Pour répondre à José comme à Sadia, nous souhaitons vous apporter un éclairage factuel au cours d’un voyage à travers l’histoire de l’IA, depuis ses origines mythologiques jusqu’à ses développements contemporains. Nous allons vous donner des bases de réflexion pour vous aider à comprendre ce qu’est l’IA, ce que vous pouvez en faire, ce que vous faites déjà !
Sommaire
#1 – Une histoire millénaire : l’IA avant l’IA
#2 – La naissance de l’IA moderne : un croisement inattendu
#3 – L’IA, carrefour de disciplines
#4 – L’IA au quotidien depuis le Web 2.0
#1 - Une histoire millénaire : l'IA avant l'IA
Bien que le terme « Intelligence Artificielle » n’ait fait son apparition qu’en 1950, son concept existait déjà dans l’inconscient humain depuis des décennies. Légendes des hommes mécaniques d’Héron d’Alexandrie, ou les récits mythologiques comme Talos, automate de bronze construit par Héphaïstos, témoignent déjà de la fascination humaine pour la création d’entités autonomes.
Adrienne Mayor, chercheuse à l’université Stanford, explique dans son ouvrage Gods and Robots que des automates apparaissent même dans des textes classiques tels que l’Iliade. Depuis la nuit des temps, l’Humain n’a eu de cesse de poursuivre cette chimère qu’est la création d’une entité intelligente, qui serait son égale. Jusqu’au jour où, par accident, cette entité s’est révélée possible.
« Au fil de l’Iliade, on rencontre de nombreux automates, des objets qui agissent d’eux-mêmes. Par exemple, les navires des Phéaciens se pilotent de manière autonome, des trépieds se meuvent pour servir le vin aux dieux de l’Olympe, des soufflets automatiques aident Héphaïstos dans son travail métallurgique. Ce dieu s’est même fabriqué un groupe de robots-servantes taillés dans de l’or »
Adrienne Mayorn, « Gods and Robots : Myths, Machines, and Ancient Dreams of Technology » (2028), Princeton University Press

#2- La naissance de l'IA moderne : un croisement inattendu, de la simulation à l'apprentissage
L’émergence de l’IA telle que nous la connaissons aujourd’hui n’était pas prédestinée, mais résulte d’une série de découvertes fortuites.
On remonte le temps ! Nous voilà en 1940. Norbert Wiener, chercheur en mathématiques appliquées, travaille sur divers projets militaires en plein cœur de la Seconde Guerre mondiale. L’un de ses travaux porte sur la création d’un nouveau système de défense contre les aéronefs, système pouvant prévoir la trajectoire d’un avion pris pour cible, en modélisant le comportement du pilote. Ce travail révéla l’ignorance de l’époque sur le fonctionnement du cerveau humain et aboutit à la découverte révolutionnaire du neurone.
Simultanément, le mathématicien et cryptologue Alan Turing travaille secrètement avec son équipe sur l’opération Ultra. Projet qui visait à créer une machine permettant de décrypter les communications allemandes émises par les machines Enigma (d’ailleurs, on vous conseille fortement le film « The Imitation Game » qui retrace à merveille cette histoire incroyable). Cette machine appelée « Bombe » n’est rien d’autre que l’ancêtre de l’ordinateur.
Sans lien apparent, ces deux découvertes vont fusionner sous la houlette des neurologues Warren McCulloch et Walter Pitts. Ces derniers se lancent dans un projet de modélisation du neurone humain via des systèmes mathématiques. C’est la naissance du « neurone formel », embryon de l’IA.
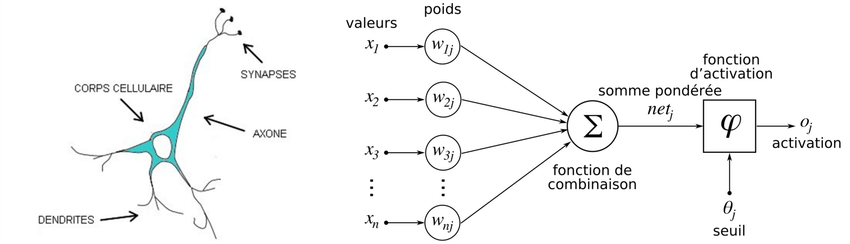
Structure d’un neurone biologique vs artificiel
En 1951, Marvin Minsky créa le SNARC, un simulateur de réseau neuronal capable de reproduire le comportement d’un rat apprenant à se déplacer dans un labyrinthe. Cinq ans plus tard, le programme Perceptron fut mis au point, permettant à une machine d’apprendre à distinguer des éléments visuels. Il semble désormais possible d’éduquer la machine grâce à la programmation informatique.
Avancées technologiques de guerre, neuroscience et informatique nourrissent au fur et à mesure ce qui deviendra l’IA en tant que domaine scientifique à part entière. Ses fondements s’officialisent à Dartmouth en 1956, pas en tant qu’outil technologique, mais en tant que discipline scientifique.

Photo des pères fondateurs de l’IA, prise lors de la conférence de Dartmouth
L’IA devient alors une opportunité de rassembler chercheurs et chercheuses autour de la volonté de comprendre le fonctionnement de l’humain, par la copie de ses mécanismes, mais pas que, la discipline devient également une opportunité de faire accélérer la recherche de manière plus globale, en diversifiant ses sources de financement.
#3 - L'IA, carrefour de disciplines et opportunités d'accélération de la Recherche
Les avancées scientifiques grâce à l’intelligence artificielle (IA) au cours des 50 dernières années sont vastes et couvrent de nombreux domaines qui vont plus loin que la simple génération d’images et de textes.
Biologie, astronomie, sociologie, linguistique, mathématique… Chacune de ces disciplines a contribué à développer la recherche autour de l’IA, et l’IA, en retour, a également permis des progrès dans ces mêmes domaines, sans pour autant remplacer ses expert•e•s.
Voici quelques exemples de ces progrès, qui ont probablement eu des impacts sur nos vies, bien avant ChatGPT :
- Biologie : accélération de la découverte de médicaments notamment grâce aux algorithmes d'apprentissage
- Physique et astronomie : les algorithmes d'IA sont une aide précieuse au traitement de quantité de données réceptionnées par les télescopes
- Chimie et matériaux : les simulations et la génération par IA peut aider à peuvent prédire des interactions d'atomes
- Écologie et climat : les algorithmes d'apprentissages couplés à l'analyse d'image facilitent la surveillance des écosystèmes et l'analyse de données capturées par des drones, capteurs ou satellites
- Mathématiques et informatique : les algorithmes permettent d'aider à résoudre des calculs complexes, notamment pour de l'optimisation de flux logistiques
- Neurosciences : les recherches autours des systèmes de neurones contribuent à mieux comprendre les mécanismes des maladies neurologiques, comme Alzheimer ou Parkinson
- Économie et sciences sociales : les différents modèles d'apprentissage aide à analyser de grandes quantités de données sur les comportements humains, à des fins d'étude
- Robotique : les différents concepts d'apprentissage permettent d'augmenter les capacités des robots pour explorer des environnements difficiles, comme l'espace, les océans profonds ou les zones de catastrophes naturelles
- Médecine : en chirurgie, les robots assistés par IA permettent de plus en plus d'interventions plus précises, et optimisent les temps d'opération, assurant de meilleures conditions de récupération pour le patient
En somme, l’IA a servi de catalyseur dans pratiquement tous les domaines scientifiques. En permettant des analyses plus rapides, des prédictions plus précises et des modèles plus sophistiqués, pour soulager l’humain des tâches ingrates, au profit de l’analyse et de la prise de décision.
L’aspect inédit de la bulle IA, dans laquelle nous sommes, c’est la mise en application publique d’IA génératives qui sont loin d’être fiables et éthiques. Mais surtout, qui se nourrissent du Web et de sa multitude d’informations pas toujours véridiques, pas toujours neutres.
En exploitant le Web comme base d’informations, nous transmettons à ces modèles d’IA nos préjugés structurels, notre héritage historique et culturel, ainsi que les biais profonds de l’humanité.
Mais pas de panique ! Nous sommes déjà passés par là, et comme d’autres modèles d’IA avant Dall-E et Claude, il a fallu passer par cette période de doute et d’hystérie avant de les cadrer correctement.
#4 - L'IA au quotidien depuis le Web 2.0
| Quelques branches de l’IA | Description |
| 🧠 Apprentissage automatique | Apprendre à partir de base de données, de manière plus ou moins encadrée : suggestion de publicité, de musique, de trajet en voiture |
| 🗣️ Traitement du langage naturel | Permettre aux ordinateurs de comprendre et générer le langage humain. Pas exemple, quand vous demandez à Chat GPT de résumer cet article de presse pour vous |
| 👁️ Vision par odinateur | Donner aux machines la capacité de « voir » et de comprendre le contenu visuel, pour piloter un véhicule ou analyser une image médicale |
| 🤖 Robotique | Créer des machines physiques autonomes, pour des tâches précises. Ce robot qui tond la pélouse, pour que vous puissiez faire vos mots croisés tranquilou sur le canapé |
| 🎨 IA créative | Doter les machines de capacité de création, à partir d’une base d’images ou de vidéos : Dall-E, Midjourney, … |
| 😊 IA émotionnelle | Comprendre et simuler les émotions humaines. On les retrouve notamment intégrées aux robots qui nous servent des boissons au restaurant, dans certains jeux vidéos, ou appli de simulation de relation. |
Chaque version de ces outils se heurte à de nombreux défis, à chaque lancement : les régulations étatiques, les cadres légaux, les attentes des utilisateurs, les impératifs des entreprises, les contraintes technologiques et les ressources disponibles.
De nombreux projets ont émergé, pour ensuite être abandonnés, comme l’IA de recrutement d’Amazon, l’IA Tay de Microsoft, ou encore Watson, l’IA d’IBM dédiée au traitement des cancers. Même des assistants virtuels populaires comme Siri et Alexa ont traversé des phases de « bad buzz » avant d’être optimisés. Cela montre que l’IA, bien qu’elle progresse rapidement, est encore dans une phase d’évolution où les itérations successives permettent d’affiner ces technologies pour répondre aux exigences complexes du monde réel.
Les MidJourney, Dall-E, Claude et ChatGPT d’aujourd’hui ne sont pas des versions définitives. Les problématiques techniques, sociales et sociétales, que ces outils abordent, feront l’objet de régulations progressives. Elles nous donneront un cadre d’usage de plus en plus sécurisant et adapté aux mondes d’aujourd’hui.
EN RÉSUMÉ
Il serait réducteur de penser l’intelligence artificielle avec dualité. Elle n’est ni bonne ni mauvaise en soi. Elle est un miroir de nos propres comportements, valeurs, et préjugés. Elle reflète les complexités et les travers de notre propre nature.
Au-delà de tous les espoirs et inquiétude qu’on peut lui attribuer, l’IA n’est pas une révolution ni une menace, c’est surtout un super moyen de comprendre le fonctionnement humain, tout en faisant avancer d’autres disciplines de la Recherche.
Son impact dépendra de l’usage que nous en ferons : pour améliorer nos vies, ou pour créer de nouveaux dangers. Nous avons tous une certaine responsabilité en tant qu’utilisateur, de nous questionner et de nous informer sur les outils utilisant l’IA. Comment pouvons-nous, à notre échelle, améliorer l’entraînement des IA pour les rendre plus éthiques ? Quel comportement devons-nous adopter lors de l’utilisation de ces outils ? Comment pouvons-nous garantir les règles d’éthiques, tant dans notre consommation de la data que dans sa création, tout en sachant qu’elle finira par être ingérée par les IA ?
POUR ALLER PLUS LOIN
Vous vous posez des questions sur l’usage de l’IA en entreprise ? Vous avez des questions en matière de d’IA et de sécurité au sein de votre organisation ? Contactez-nous ! Nous nous ferons un plaisir de répondre à vos questions
Pour aller plus loin
- Recherches du professeur Frédéric Fürst, Université d’Amiens : https://home.mis.u-picardie.fr/~furst/docs/3-Naissance_IA.pdf
- That’s IA.com : https://www.thats-ai.org/fr-CH
- Data Science Institute : https://datascience.uchicago.edu/news/nsf-awards-20-million-to-build-ai-models-that-predict-scientific-discoveries-and-technological-advancements/
- Science Exchange : https://scienceexchange.caltech.edu/topics/artificial-intelligence-research?utm_term%C2%A0
- France Culture : https://www.radiofrance.fr/franceculture/aux-origines-de-l-intelligence-artificielle-1738879
- « Gods and Robots », Adrienne Mayor, (2018)
- « Préjugés contre les femmes et les filles dans les grands modèles de langage », étude de l’UNESCO
- « Artificial Intelligence – The Revolution Hasn’t Happened Yet » par Michael Jordan (2018)
- « Algorithmic Bias Detection and Mitigation: Best Practices and Policies to Reduce Consumer Harms » par Ben Green et Lily Hu (2018)
- « Artificial Intelligence: A Guide for Thinking Humans » par Melanie Mitchell (2019)