
Who Run The Tech 2024 : Ce que les dev’ de la Cool Team ont appris
En novembre dernier, la Cool Team a empaqueté son goûter et sa trousse de crayons, direction Rennes pour faire le plein d’enseignements auprès des speakeuses de Who Run The Tech. On vous l’avait dit dans notre newsletter (faut la lire, vous ratez un truc), on ne sort pas souvent de nos bureaux, mais quand on le fait, on ne rigole pas avec nos choix d’événement.
Ça fait un moment, mais ce n’est jamais trop tard quand il y a quelque chose à transmettre
Nos développeurs ont ainsi pu tester le degré de leur savoir sur différents domaines allant de la cybersécurité aux pratiques du craft, en passant par des approches de code pure, de conception, d’organisation du travail. Parce que c’est aussi, et surtout ça, le métier de dév, c’est entraîner sa curiosité, cultiver la remise en question de ses acquis, et nourrir ses compétences auprès de ses pairs.
Erwan, Florence et Marie vous proposent un top 5 des conférences auxquelles ils ont pu participer tout au long d’une journée d’événement comptabilisant pas moins d’une trentaine de conférences, quickies et ateliers. On va vous parler des choses qu’on a apprises, celles qui nous ont marquées et ce qu’on compte faire de ces nouveaux savoirs dans notre métier de tous les jours.

On n'a pas pu tout voir, mais on a assisté à tout ça
JAMing with Performance - Alex Palma
Erwan, notre Cool ingénieur, a assisté à la conférence d’Alex Palma, développeuse font-end chez Zenika Brest, portant sur la Jamstack.
De quoi on parle ?
La Jamstack, acronyme de Javascript API Markup, est une approche, une architecture utilisée pour construire des sites web. Elle a été créée en 2015 par Mathias Biilmann, PDG de la firme de cloud computing Netlify.
L’objet de la conférence mettait en lumière l’obsolescence critiquée de cette architecture. Décrite comme « trop vieille » et « plus adaptée » par les développeurs, notamment face aux évolutions du secteur (les sites ultra personnalisés et très dynamiques), ou à l’apparition de frameworks plus modernes comme Next.js, entre autres.
Qu’est-ce qu’on a appris ?
Aujourd’hui, la Jamstack est encore massivement utilisée, sans que cette étiquette soit forcément collée sur ses lignes de code. C’est une pratique qui est entrée dans les fondements du développement front-end, pour en faire complètement partie. Elle permet notamment de travailler sur un front autonome et autosuffisant, permettant de créer des applications réfléchies sous l’angle de l’écoconception.
La désuétude n’est pas une caractéristique de la Jamstack qui reste pertinente pour des projets relativement simples et statiques, comme des sites vitrine, des landing pages, ou la création de blogs. L’approche se révélera moins adaptée pour des projets interactifs, où le dynamique est omniprésent.
Qu’est-ce qu’on va appliquer ?
L’adage « Être statique par défaut et appliquer de la complexité s’il faut » est une pratique intéressante mise en avant par Alex qui propose de profiter de la Jamstack pour ce qu’elle a à offrir d’efficace et de stable, à savoir minimiser les couches successives de dynamismes quand il n’y a pas d’objectif concret.

TDD, décortiqué, pratiqué, démystifié - Jacqueline Rwanyindo
Nos deux développeuses Florence et Marie sont pu participer à l’atelier proposé par Jacqueline Rwanyindo, Ingénieure logiciel, chez Ippon Technologies abordant la pratique du TDD.
De quoi on parle ?
Le TDD est une pratique Craft qui permet de concevoir des logiciels par itérations successives très courtes. Chaque itération est réalisée grâce à la résolution d’un problème dédié, via l’exécution de tests, et la prise en compte de feedback. Le code n’est créé qu’en dernière étape, et a pour vocation d’être le plus simple possible.
L’une des pratiques les plus courantes, et les plus répandues en TDD, est le « Baby Steps », expliqué lors de l’atelier via la réalisation du kata FizzBuzz.
Qu’est-ce qu’on a appris ?
Le kata met en lumière l’importance de la rédaction de tests en amont de la rédaction du code. Prévoir ses tests permet de :
- Alléger la charge mentale
- Organiser son travail
- Gagner du temps pour produire un code de qualité, puisque cette réflexion force les développeur.eures à anticiper les anomalies
Qu’est-ce qu’on va appliquer ?
La rédaction de listes de tests est une pratique que l’on compte appliquer dans nos méthodologies, suivant deux temporalités : en phrase de conception et en phase de développement (production de code).

Améliorer l'implémentation du feature flip pour réussir à avoir du flow - Dorra Bartaguiz
Nous étions plusieurs membres de l’agence à assister à cette conférence, quelque peu intrigués par le titre et encore plus par le contenu. Dorra Bartaguiz, CTO chez Arolla, a magiquement transformé l’utilisation du « feature flip » en une liste de do’s and dont’s, pour finalement ne nous donner qu’une seule et bonne raison d’utiliser cette fonction : éviter de le faire. Malin.
De quoi on parle ?
Le Feature flipping est un mécanisme permettant d’activer, ou désactiver une fonctionnalité directement en production, sans avoir à re-déployer du code.
Qu’est-ce qu’on a appris ?
Le feature flipping s’avère parfois problématique. On le déploie pour contrer les conséquences d’un code mal conçu, pour activer/désactiver un bout code non terminé, ou activer/désactiver une fonctionnalité qui vient d’être livrée, mais qui ne correspondrait pas à la demande du client.
Dorra Bartaguiz a créé cette conférence dans le but de désamorcer la mauvaise utilisation du feature flip, mais aussi et surtout, d’améliorer son utilisation chez les dévs.
Elle a présenté différentes méthodes de mise en action du feature flip, qui sont courantes, et plus ou moins saines comme :
- Trunk base developpement : Travailler sur le tronc commun du code, pas de branches
- Branch base development : Utiliser une seule feature par branche, avec un merge en fin de développement
- Livraison partielle : Éviter l’effet tunnel pour réduire le cycle de vie des branches
- Activation selon contexte : Activer/désactiver selon des situations, des déclencheurs précis
- Dépendance externe : Activer/désactiver des fonctions selon les usages des utilisateurs finaux
Pour ne pas succomber à la solution de facilité, Dorra propose une alternative sécuritaire et pérenne : le Circuit breaker.

Qu’est-ce qu’on va appliquer ?
Même si, de base, la technique du feature flip est peu utilisée dans les principes de développement de nos Cool Devs, elle reste une méthode intéressante de part ce qu’elle révèle. Elle appuie l’importance de réfléchir avant de coder. Réfléchir sa conception est essentiel pour éviter l’abus du feature flip, qui en plus de rendre impossible la maintenance d’une application, ne permet pas de créer du code simple et clair.
La réflexion de la conception passe par le découpage des tâches en amont, l’implication du Métier et des Utilisateurs finaux, méthodo déjà largement inscrite dans nos principes de dev, mais qu’on peut étoffer grâce au mind mapping.

Décodons nos pipelines : Comprendre pour mieux déployer - Hafsa Elmaizi
Nos trois développeurs ont assisté à la conférence de Hafsa Elmaizi, Développeuse Back-End chez SII, pour tenter d’en apprendre plus au sujet des pipelines CI/CD.
De quoi on parle ?
Un pipeline est une série d’étapes à suivre lorsqu’on déploie du code, qui permet de vérifier la qualité du code, sa sécurité et sa fiabilité. Les pipelines permettent également de déployer automatiquement le code sur un serveur.
Qu’est-ce qu’on a appris ?
Comprendre ses pipelines, c’est cool ! Savoir écrire ses pipelines, c’est encore plus cool ! Généralement pris en charge par les DevOps, la configuration de pipeline par les développeur.euses comporte de nombreux avantages :
-
- Responsabilisation des équipes de développement sur le déploiement
- Alignement des équipes de dev et devOps
- Détection et résolution rapide d’erreurs de déploiement
- Optimisation sur la qualité de code
- Anticipation et adaptabilité en cas d’incident et autres
Grâce à cette compétence, on peut facilement :
-
- Lancer des tests unitaires & d’intégration
- Réaliser des tests de charge
- Tester différents niveaux de sécurité (code, dépendance, etc.)
- S’assurer des livraisons continues vérifiées
Qu’est-ce qu’on va appliquer ?
Des templates de configuration de pipelines existent et ils pourraient se révéler intéressants à étudier, dans le cadre de nos projets futurs.

Représentation des scénarios d'attaques avancées - Valérie Viet Triem Tong
Notre développeuse-to-be Marie a assisté à la conférence de Valérie Viet Triem Tong, Professeure en Cybersécurité à la CentraleSupelec, et chercheuse, sur les scénarii plus ou moins longs d’attaques sur des systèmes d’information.
De quoi on parle ?
Valérie Viet Triem Tong propose de plonger avec elle dans son sujet d’étude de prédilection, sujet auquel elle a déjà dédié 10 ans de sa carrière, les APT.
APT signifie « Advanced Persistent Threats », et désigne un attaquant avec un objectif, qui va prendre le temps nécessaire, parfois des années, pour s’infiltrer dans un SI. Les APT sont les attaques les plus difficiles à reconnaître et à anticiper. Ce type d’attaque étant très peu documentée du fait du protectionnisme des entreprises sur cette typologie de crise interne.
Qu’est-ce qu’on a appris ?
Malgré le manque de ressources et de data, un Cyber Kill Chain est créé en 2011, permettant d’identifier plusieurs étapes dans les attaques APT :
- Entrée dans le SI par une des nombreuses entrées : à ce stade, l’attaquant ne sait pas vraiment où il se trouve, et doit donc « explorer » autour de lui
- Propagation dans le réseau : prendre le maximum d’informations, jusqu’à trouver le service cible, souvent de manière visible
- Il disparaît, travaille en parallèle pour simuler l’attaque grâce aux infos qu’ils a récupérées. Cette phase d’essai/erreur peut durer des semaines, mois ou années avant de produire une version « finalisée » d’intrusion
- Il revient avec son attaque consolidée
Bien que les premiers modèles apparaissent, le manque de données réelles freine la recherche. En effet, une application attaquée sera très souvent immédiatement, ne permettant pas de garder une photo de l’instant T de l’attaque.
Pour remédier à cette pénurie, Valérie Viet Triem Tong lance un appel aux entreprises favorables à un travail avec son équipe, dans le but de faire avancer les recherches scientifiques pour faire évoluer le modèle, en collaboration avec Pirat/’) ;, son collectif de chercheur.euses.
Qu’est-ce qu’on va appliquer ?
Les conseils simples, mais efficaces, de Valérie sur les réflexes cybers accessibles :
– Changer son mot de passe régulièrement
– Éviter les doublons d’identifiants
– Mettre en place routine régulière de ces changements
Autant de pratiques que l’on souhaite enseigner de manière systématique à nos clients, comme un devoir professionnel, notre serment d’Hippocrate à nous.
EN RÉSUMÉ
Who Run The Tech s’affirme, année après année, comme un événement incontournable dans le paysage de la tech, grâce à la richesse de ses interventions et à sa vision inclusive et engagée. En donnant la parole à des femmes expertes du secteur, cet événement ne se limite pas à transmettre des savoirs : il agit comme un levier de changement, en mettant en lumière les problématiques d’inclusivité et leurs conséquences sur l’innovation. Une initiative inspirante qui, au-delà de rassembler, invite chacun et chacune à repenser le futur de la tech de manière plus juste et équitable.

Who Run the Tech ? Elles ! Et on est allé leur parler
IA explicable et sororité
Cécile Hannotte, Data Scientist chez OnePoint, nous a parlé des enjeux de la transparence des IA. Le sujet de sa conférence « IA-404 : Explication not found« nous éclaire sur la démarche d’une IA qu’on entraîne à se justifier. Elle aborde aussi avec nous l’importance de la sororité dans le monde de la tech
Utiliser TestContainers
Adriana Nava Aguilar, développeuse et consultante chez Néosoft, aborde à notre micro son rôle en tant qu’ambassadrice du réseau Women TechMakers avant de répondre à notre problématique d’uniformisation des tests. Sa conférence, « TestContainers : un allié pour faire des tests d’intégration sans douleur », propose de revoir les fondamentaux de cet outil.
La Jamstack, c'est obsolète ?
Alex Palma, développeuse front-end et consultante chez Zenika, nous parle du challenge qu’a représenté la création de sa conférence « JAMing with Performance ».
Ces astuces de dev' qui n'en sont pas
Amy Ndiaye est développeuse web chez Younup. Elle a créé la conférence « FBI (Fausse Bonne Intégration) : ces astuces et bonnes pratiques qui sabotent vos sites et applications web » dans le but de réduire le nombre de tickets récurrents, notamment lorsqu’on touche à l’accessibilité d’un site web
N'utilisez pas le feature flipping
Dorra Bartaguiz, CTO chez Arolla, a développé sa conférence « Améliorer l’implémentation du feature flip pour réussir à avoir du flow » à la suite d’échanges à propos du feature flip sur les réseaux. Elle en tire une présentation proposant une alternative saine à cette pratique
Les jeux vidéos inclusifs
Noélie Roux est Engineering Manager, et aussi membre de l’association Game’Her qui promeut l’inclusivité dans les secteurs du jeux vidéo et du streaming. Cette seconde activité l’a amené à créer sa conférence « Succès débloqué : rendre son jeu vidéo accessible ».
In Mob we trust
Marjorie Aubert et Manon Carbonne, toutes deux développeuses web chez Comet et Shodo, font également parti du meetup Mob Programming France. Elles partagent avec nous leur passion pour le mob programming, ses avantages, ses bénéfices et ses possibles
La cyber pour tous
Valérie Viet Triem Tong est Professeur en Cybersécurité à CentraleSupelec, elle est aussi responsable d’une équipe de recherche appelée PIRAT\’);. On lui a demandé de nous donner, selon elle, les réflexes à avoir en termes de cybersécurité pour bien protéger son smartphone, son ordi, mais aussi, les autres utilisateurs.

L'intelligence artificielle : Histoire, Réalités et Fantasmes
L’intelligence artificielle est sur toutes les lèvres. Qu’il s’agisse de prédictions apocalyptiques ou de promesses de révolutions technologiques : l’IA fascine autant qu’elle inquiète. Les spéculations sur ces IA super-intelligentes, autonomes et capables de remplacer l’Humain sont au cœur de tous les talk-show, de tous les argumentaires journalistiques, de tous les débats en repas de famille.
On nous demande souvent de prendre position sur le sujet d’ailleurs, et on admet que l’exercice n’est pas facile pour nous. Vous commencez à nous connaître, chez Cool IT, c’est toujours « ni oui ni non ». On en a déjà parlé sous le prisme de la cybersécurité et de la vulgarisation de jargon.
Cependant, il semblerait que vous attendiez plus de ressources de notre part pour rassurer tonton José persuadé que « L’IA va nous détruire », ou contenir Sadia du marketing convaincu que « Si on s’y met pas, on est mort ! », sans trop savoir ce que votre entreprise pourrait faire avec.
Pour répondre à José comme à Sadia, nous souhaitons vous apporter un éclairage factuel au cours d’un voyage à travers l’histoire de l’IA, depuis ses origines mythologiques jusqu’à ses développements contemporains. Nous allons vous donner des bases de réflexion pour vous aider à comprendre ce qu’est l’IA, ce que vous pouvez en faire, ce que vous faites déjà !
Sommaire
#1 – Une histoire millénaire : l’IA avant l’IA
#2 – La naissance de l’IA moderne : un croisement inattendu
#3 – L’IA, carrefour de disciplines
#4 – L’IA au quotidien depuis le Web 2.0
#1 - Une histoire millénaire : l'IA avant l'IA
Bien que le terme « Intelligence Artificielle » n’ait fait son apparition qu’en 1950, son concept existait déjà dans l’inconscient humain depuis des décennies. Légendes des hommes mécaniques d’Héron d’Alexandrie, ou les récits mythologiques comme Talos, automate de bronze construit par Héphaïstos, témoignent déjà de la fascination humaine pour la création d’entités autonomes.
Adrienne Mayor, chercheuse à l’université Stanford, explique dans son ouvrage Gods and Robots que des automates apparaissent même dans des textes classiques tels que l’Iliade. Depuis la nuit des temps, l’Humain n’a eu de cesse de poursuivre cette chimère qu’est la création d’une entité intelligente, qui serait son égale. Jusqu’au jour où, par accident, cette entité s’est révélée possible.
« Au fil de l’Iliade, on rencontre de nombreux automates, des objets qui agissent d’eux-mêmes. Par exemple, les navires des Phéaciens se pilotent de manière autonome, des trépieds se meuvent pour servir le vin aux dieux de l’Olympe, des soufflets automatiques aident Héphaïstos dans son travail métallurgique. Ce dieu s’est même fabriqué un groupe de robots-servantes taillés dans de l’or »
Adrienne Mayorn, « Gods and Robots : Myths, Machines, and Ancient Dreams of Technology » (2028), Princeton University Press

#2- La naissance de l'IA moderne : un croisement inattendu, de la simulation à l'apprentissage
L’émergence de l’IA telle que nous la connaissons aujourd’hui n’était pas prédestinée, mais résulte d’une série de découvertes fortuites.
On remonte le temps ! Nous voilà en 1940. Norbert Wiener, chercheur en mathématiques appliquées, travaille sur divers projets militaires en plein cœur de la Seconde Guerre mondiale. L’un de ses travaux porte sur la création d’un nouveau système de défense contre les aéronefs, système pouvant prévoir la trajectoire d’un avion pris pour cible, en modélisant le comportement du pilote. Ce travail révéla l’ignorance de l’époque sur le fonctionnement du cerveau humain et aboutit à la découverte révolutionnaire du neurone.
Simultanément, le mathématicien et cryptologue Alan Turing travaille secrètement avec son équipe sur l’opération Ultra. Projet qui visait à créer une machine permettant de décrypter les communications allemandes émises par les machines Enigma (d’ailleurs, on vous conseille fortement le film « The Imitation Game » qui retrace à merveille cette histoire incroyable). Cette machine appelée « Bombe » n’est rien d’autre que l’ancêtre de l’ordinateur.
Sans lien apparent, ces deux découvertes vont fusionner sous la houlette des neurologues Warren McCulloch et Walter Pitts. Ces derniers se lancent dans un projet de modélisation du neurone humain via des systèmes mathématiques. C’est la naissance du « neurone formel », embryon de l’IA.
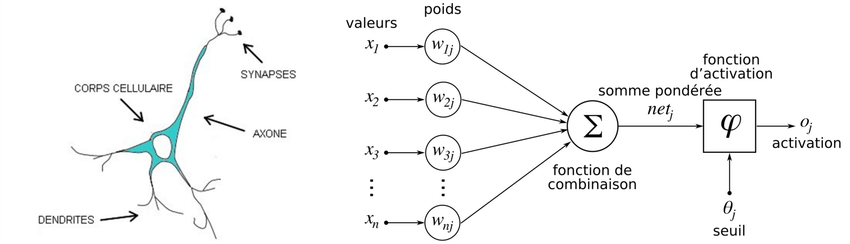
Structure d’un neurone biologique vs artificiel
En 1951, Marvin Minsky créa le SNARC, un simulateur de réseau neuronal capable de reproduire le comportement d’un rat apprenant à se déplacer dans un labyrinthe. Cinq ans plus tard, le programme Perceptron fut mis au point, permettant à une machine d’apprendre à distinguer des éléments visuels. Il semble désormais possible d’éduquer la machine grâce à la programmation informatique.
Avancées technologiques de guerre, neuroscience et informatique nourrissent au fur et à mesure ce qui deviendra l’IA en tant que domaine scientifique à part entière. Ses fondements s’officialisent à Dartmouth en 1956, pas en tant qu’outil technologique, mais en tant que discipline scientifique.

Photo des pères fondateurs de l’IA, prise lors de la conférence de Dartmouth
L’IA devient alors une opportunité de rassembler chercheurs et chercheuses autour de la volonté de comprendre le fonctionnement de l’humain, par la copie de ses mécanismes, mais pas que, la discipline devient également une opportunité de faire accélérer la recherche de manière plus globale, en diversifiant ses sources de financement.
#3 - L'IA, carrefour de disciplines et opportunités d'accélération de la Recherche
Les avancées scientifiques grâce à l’intelligence artificielle (IA) au cours des 50 dernières années sont vastes et couvrent de nombreux domaines qui vont plus loin que la simple génération d’images et de textes.
Biologie, astronomie, sociologie, linguistique, mathématique… Chacune de ces disciplines a contribué à développer la recherche autour de l’IA, et l’IA, en retour, a également permis des progrès dans ces mêmes domaines, sans pour autant remplacer ses expert•e•s.
Voici quelques exemples de ces progrès, qui ont probablement eu des impacts sur nos vies, bien avant ChatGPT :
- Biologie : accélération de la découverte de médicaments notamment grâce aux algorithmes d'apprentissage
- Physique et astronomie : les algorithmes d'IA sont une aide précieuse au traitement de quantité de données réceptionnées par les télescopes
- Chimie et matériaux : les simulations et la génération par IA peut aider à peuvent prédire des interactions d'atomes
- Écologie et climat : les algorithmes d'apprentissages couplés à l'analyse d'image facilitent la surveillance des écosystèmes et l'analyse de données capturées par des drones, capteurs ou satellites
- Mathématiques et informatique : les algorithmes permettent d'aider à résoudre des calculs complexes, notamment pour de l'optimisation de flux logistiques
- Neurosciences : les recherches autours des systèmes de neurones contribuent à mieux comprendre les mécanismes des maladies neurologiques, comme Alzheimer ou Parkinson
- Économie et sciences sociales : les différents modèles d'apprentissage aide à analyser de grandes quantités de données sur les comportements humains, à des fins d'étude
- Robotique : les différents concepts d'apprentissage permettent d'augmenter les capacités des robots pour explorer des environnements difficiles, comme l'espace, les océans profonds ou les zones de catastrophes naturelles
- Médecine : en chirurgie, les robots assistés par IA permettent de plus en plus d'interventions plus précises, et optimisent les temps d'opération, assurant de meilleures conditions de récupération pour le patient
En somme, l’IA a servi de catalyseur dans pratiquement tous les domaines scientifiques. En permettant des analyses plus rapides, des prédictions plus précises et des modèles plus sophistiqués, pour soulager l’humain des tâches ingrates, au profit de l’analyse et de la prise de décision.
L’aspect inédit de la bulle IA, dans laquelle nous sommes, c’est la mise en application publique d’IA génératives qui sont loin d’être fiables et éthiques. Mais surtout, qui se nourrissent du Web et de sa multitude d’informations pas toujours véridiques, pas toujours neutres.
En exploitant le Web comme base d’informations, nous transmettons à ces modèles d’IA nos préjugés structurels, notre héritage historique et culturel, ainsi que les biais profonds de l’humanité.
Mais pas de panique ! Nous sommes déjà passés par là, et comme d’autres modèles d’IA avant Dall-E et Claude, il a fallu passer par cette période de doute et d’hystérie avant de les cadrer correctement.
#4 - L'IA au quotidien depuis le Web 2.0
| Quelques branches de l’IA | Description |
| 🧠 Apprentissage automatique | Apprendre à partir de base de données, de manière plus ou moins encadrée : suggestion de publicité, de musique, de trajet en voiture |
| 🗣️ Traitement du langage naturel | Permettre aux ordinateurs de comprendre et générer le langage humain. Pas exemple, quand vous demandez à Chat GPT de résumer cet article de presse pour vous |
| 👁️ Vision par odinateur | Donner aux machines la capacité de « voir » et de comprendre le contenu visuel, pour piloter un véhicule ou analyser une image médicale |
| 🤖 Robotique | Créer des machines physiques autonomes, pour des tâches précises. Ce robot qui tond la pélouse, pour que vous puissiez faire vos mots croisés tranquilou sur le canapé |
| 🎨 IA créative | Doter les machines de capacité de création, à partir d’une base d’images ou de vidéos : Dall-E, Midjourney, … |
| 😊 IA émotionnelle | Comprendre et simuler les émotions humaines. On les retrouve notamment intégrées aux robots qui nous servent des boissons au restaurant, dans certains jeux vidéos, ou appli de simulation de relation. |
Chaque version de ces outils se heurte à de nombreux défis, à chaque lancement : les régulations étatiques, les cadres légaux, les attentes des utilisateurs, les impératifs des entreprises, les contraintes technologiques et les ressources disponibles.
De nombreux projets ont émergé, pour ensuite être abandonnés, comme l’IA de recrutement d’Amazon, l’IA Tay de Microsoft, ou encore Watson, l’IA d’IBM dédiée au traitement des cancers. Même des assistants virtuels populaires comme Siri et Alexa ont traversé des phases de « bad buzz » avant d’être optimisés. Cela montre que l’IA, bien qu’elle progresse rapidement, est encore dans une phase d’évolution où les itérations successives permettent d’affiner ces technologies pour répondre aux exigences complexes du monde réel.
Les MidJourney, Dall-E, Claude et ChatGPT d’aujourd’hui ne sont pas des versions définitives. Les problématiques techniques, sociales et sociétales, que ces outils abordent, feront l’objet de régulations progressives. Elles nous donneront un cadre d’usage de plus en plus sécurisant et adapté aux mondes d’aujourd’hui.
EN RÉSUMÉ
Il serait réducteur de penser l’intelligence artificielle avec dualité. Elle n’est ni bonne ni mauvaise en soi. Elle est un miroir de nos propres comportements, valeurs, et préjugés. Elle reflète les complexités et les travers de notre propre nature.
Au-delà de tous les espoirs et inquiétude qu’on peut lui attribuer, l’IA n’est pas une révolution ni une menace, c’est surtout un super moyen de comprendre le fonctionnement humain, tout en faisant avancer d’autres disciplines de la Recherche.
Son impact dépendra de l’usage que nous en ferons : pour améliorer nos vies, ou pour créer de nouveaux dangers. Nous avons tous une certaine responsabilité en tant qu’utilisateur, de nous questionner et de nous informer sur les outils utilisant l’IA. Comment pouvons-nous, à notre échelle, améliorer l’entraînement des IA pour les rendre plus éthiques ? Quel comportement devons-nous adopter lors de l’utilisation de ces outils ? Comment pouvons-nous garantir les règles d’éthiques, tant dans notre consommation de la data que dans sa création, tout en sachant qu’elle finira par être ingérée par les IA ?
POUR ALLER PLUS LOIN
Vous vous posez des questions sur l’usage de l’IA en entreprise ? Vous avez des questions en matière de d’IA et de sécurité au sein de votre organisation ? Contactez-nous ! Nous nous ferons un plaisir de répondre à vos questions
Pour aller plus loin
- Recherches du professeur Frédéric Fürst, Université d’Amiens : https://home.mis.u-picardie.fr/~furst/docs/3-Naissance_IA.pdf
- That’s IA.com : https://www.thats-ai.org/fr-CH
- Data Science Institute : https://datascience.uchicago.edu/news/nsf-awards-20-million-to-build-ai-models-that-predict-scientific-discoveries-and-technological-advancements/
- Science Exchange : https://scienceexchange.caltech.edu/topics/artificial-intelligence-research?utm_term%C2%A0
- France Culture : https://www.radiofrance.fr/franceculture/aux-origines-de-l-intelligence-artificielle-1738879
- « Gods and Robots », Adrienne Mayor, (2018)
- « Préjugés contre les femmes et les filles dans les grands modèles de langage », étude de l’UNESCO
- « Artificial Intelligence – The Revolution Hasn’t Happened Yet » par Michael Jordan (2018)
- « Algorithmic Bias Detection and Mitigation: Best Practices and Policies to Reduce Consumer Harms » par Ben Green et Lily Hu (2018)
- « Artificial Intelligence: A Guide for Thinking Humans » par Melanie Mitchell (2019)

Bien utiliser les différents termes de l'Intelligence Artificielle
Il faut qu’on vous avoue quelque chose…C’est très difficile à exprimer, alors nous irons droit au but ! L’Intelligence Artificielle ne sert pas à travailler, ni à prendre des décisions à votre place !
Pourquoi ? Parce que c’est tout simplement irréalisable pour l’instant. Les recherches autour des Intelligences Artificielles avancent d’année en année. Nous découvrons des programmes très impressionnants tels que ChatGPT, Lensa ou Dall•E, qui annoncent, pour le futur, de nouvelles opportunités de support au travail des Humains. Mais ce n’est pas une raison pour dire n’importe quoi sur les IA, et ce pour plusieurs raisons :
– Pour ne pas se fier à 100% aux contenus des IA, sans vérification ;
– Pour ne pas décevoir les utilisateurs ;
– Pour ne pas décevoir des investisseurs potentiels ;
– Pour ne pas limiter les IA à un sujet informatique ;
– Pour recruter des personnes qualifiées etc.
Vous l’aurez compris, plus vous utiliserez correctement les termes et le vocabulaire de l’Intelligence Artificielle, plus vous serez à même de ne pas vous faire avoir, ou de générer trop d’attente autour d’un projet d’IA.
On vous explique ?
#1 — Il n’y a pas une, mais DES Intelligences Artificielles
Au sens stricte, l’Intelligence Artificielle est un ensemble de théories, techniques et disciplines, dont l’objectif est de doter la machine d’une simulation d’intelligence humaine, sur plusieurs périmètres :
- L’apprentissage ;
- La communication ;
- L'aide à la décision ;
- La résolution de problème ;
- La création ;
- La fabrication ;
- La prédiction...
- Ressentir
- Construire une opinion
- Exprimer des émotions
- S’adapter
- Tirer des leçons personnelles…
Au même titre qu’il n’y a pas un seul modèle d’intelligence chez l’Humain, il y a plusieurs modèles d’Intelligence Artificielle :
L’IA faible ou étroite – ANI
- Il s’agit des IA mises en œuvre aujourd’hui sur différents services : chatbot, moteur de recherche, outil de ciblage, reconnaissance faciale, reconnaissance vocale.
- Elles sont dites « faibles » car elles sont configurées en amont pour imiter une action unique, de manière automatique, à partir de bases de connaissance définies et encadrées.
- Elles ne sont pas pleinement autonomes, et nécessitent des vérifications.
L’IA forte ou générale – AGI
- Ce type d’IA n’est aujourd’hui qu’au stade du concept et de l’expérimentation.
- Pour passer d’une IA faible à une IA forte, il faudrait qu’elle soit en mesure de s’adapter à l’imprévu, apprendre d’elle-même, raisonner et comprendre « exactement » comme un humain, pour résoudre des problèmes, et réagir à des situations.
La super intelligence – ASI
- C’est l’IA de science-fiction, à savoir une IA qui agirait exactement comme l’Humain
- C’est l’IA qui aurait son individualité, et sa conscience propre, quitte à surpasser l’Humain, grâce à des capacités d’analyse et de ressenti qui lui seraient propre
Où est-ce qu’on veut en venir ?
- Il faut être vigilant dans la manière de présenter un projet d’IA, afin de ne pas décevoir l’utilisateur…ou des financeurs, avec une solution miracle
- On ne peut pas réduire l’IA à une discipline purement informatique et technique
- L’activité d’une IA doit toujours être supervisé et vérifié
Exemple d’abus
de langage
- Sens n°1 / Catégorie Abus Gentil : Notre entreprise investit dans l’automatisation pour faciliter certaines tâches
- Sens n°2 / Catégorie Abus Abusé : Notre entreprise n’investit dans rien du tout, mais parler d’IA c’est bon pour l’image
- Sens n°1 / Catégorie Abus Gentil : Notre CRM segmente bien vos fichiers clients, suggère des actions, automatise les envois d’e-mail
- Sens n°2 / Catégorie Abus Abusé : Les commerciaux ne connaissent pas bien le produit, mais maîtrisent les mots à la mode
- Sens n°1 / Catégorie Abus Gentil : Notre solution facilite la prise de décision, en organisant bien les données
- Sens n°2 / Catégorie Abus Abusé : Nous utilisons des anglicismes à la mode, pour vendre une solution qui fait de jolis tableaux de bords
#2 – Les notions à ne pas confondre
IA et Machine Learning
Le Machine Learning est un modèle d’apprentissage pour les IA. À partir d’un ensemble de données, d’algorithmes et de modèles mathématiques, le Machine Learning permet à un système informatique de réaliser des actions, sans être directement dirigé par l’Humain.

Le Machine Learning est exploité dans plusieurs champs d’application comme la reconnaissance vocale (Siri, Alexa), la vision par ordinateur (analyse d’images), la prédiction de résultats, la compréhension de langage naturel (chatbot), reconnaissance d’image (recherche inversée), le transport autonome, la recommandation, le ciblage publicitaire…
IA et Deep Learning
Le Deep Learning est un autre modèle d’apprentissage pour les IA. Ce modèle vise à intégrer des réseaux de neurones dits « profonds » pour permettre aux IA d’analyser des données, de manière plus subtile.
Contrairement au Machine Learning qui traite la donnée de manière linéaire, le Deep Learning apprend aux IA à traiter les données par couche, de plus évident au plus abstrait, comme un arbre de décision géant. On l’exploite aujourd’hui pour la reconnaissance d’image, la reconnaissance vocale, la compréhension de langage naturel, la génération de contenu, la traduction, la détection de fraude…

IA et Algorithme
En informatique, un algorithme est une suite d’étape que l’on rédige, qu’on modélise, à partir de différentes informations, pour qu’un système informatique génère des résultats ou des actions.
Les algorithmes ne sont pas des IA, mais une partie de ce qui les fait fonctionner.
IA et Automatisation
L’automatisation n’est pas qu’un procédé informatique, on peut automatiser des choses de manière mécanique, en faisant appel à l’électronique, sans utiliser de systèmes informatiques.
- En informatique, l’automatisation consiste à utiliser des algorithmes pour effectuer des tâches sans l’intervention directe de l’Humain. Exemple : l’envoi d’e-mail programmé
- Il n’y a pas systématiquement une IA derrière un système automatisé.
IA et Chatbot
Un chatbot est un programme informatique capable de converser avec l’Humain, en langage plus ou moins naturel. Pour ce type de service aussi, il n’y a pas systématiquement une IA derrière.
- Les chatbots, sans IA, fonctionnent plutôt comme une F.A.Q dynamique, avec des questions et des réponses pré-enregistrées, à partir de mots-clés.
- Les chatbots, qui intègrent une IA, analyse le langage, apprennent au fur et mesure des échanges, et sont en capacité d’affiner leur réponse.
- Les faux chatbots vous font échanger avec des Humains. Ceux sont des chats quoi !

Les mondes imaginaires sont-ils toujours des safe place pour les personnes minorisées ?
Pendant longtemps, les jeux vidéo qui se déroulaient dans des mondes imaginaires, pouvaient être un moyen d’affirmation de soi pour les personnes minorisées. Ou un moyen de s’évader d’un système oppressif.
L’avatar, notamment, pouvait être, aussi bien une réplique de soi-même, qu’une projection de ce que la société nous empêche d’être. Le choix d’un rôle, du contrôle d’une histoire, pouvait être un moyen de ré-appropriation de ce qui nous échappe IRL[1].
Pourtant, 83%[2] des gamers, de 18-45 ans, ont subi du harcèlement en jouant aux jeux vidéo, dont 71% allant jusqu’à des agressions graves : menaces physiques, stalking[3], chantage…Ces agissement sont en augmentation depuis 2019.
Pour 1 gamer sur 2, les raisons sont liées à leur religion, leurs identités de genre, leur orientation sexuelle ou leurs origines. Même dans un monde imaginaire, iels se retrouvent alors, autant stigmatisé·e·s que dans leur quotidien « réel ».
[1] IRL = In Real Life, Dans la vraie vie
[2] Rapport de l’ONG ADL “Hate is No Game: Harassment and Positive Social Experiences in Online Games 2021”
[3] Stalking = Fait de traquer une personne en ligne et/ou dans la vraie vie
#1 C’est quoi une safe place ?
C’est un espace bienveillant et protecteur, où des personnes minorisées et discriminées, se retrouvent pour différentes activités, très souvent empêchées ou polluées par des personnes oppressives.
Ces espaces sont aussi bien physiques que virtuels. Ils sont souvent fondés, par et pour les personnes minorisées, avec ou sans leurs allié•e•s
Dans les milieux du jeu, les safe place sont surtout créés pour jouer en ligne loin des « haters » » et des » trolls », mais aussi pour donner de la visibilité à des profils de joueur•ses qu’on ne voit pas assez.
On les retrouve notamment dans des associations militantes, des groupes de discussion ou des applications de mise en relation.
#2 C’est quoi un HATER et un TROLL ?
Hater
[ɛ.tœʁ] Nom, anglicisme
Personne qui dénigre d’autres personnes sur internet, en raison d’un critère qu’iel déteste, un désaccord, ou un biais d’intolérance
Troll
[tʀ ɔl] Nom, originaire de Suède
Personne ou message, qui vise à provoquer et/ou susciter des polémiques afin de perturber une discussion ou une personne
#4 Comment en sommes-nous arrivés là ?
Dans les faits, le harcèlement et agressions en ligne, ont toujours été présents dans les communautés de jeux en ligne. On peut pointer plusieurs phénomènes qui ont contribué à renforcer ces comportements :
- L’augmentation de la pratique du jeu multi-joueur en ligne, associé à des canaux de discussion, où les joueurses discutent pendant le jeu (chat, live streaming, salon audio…)
- L’évolution des moyens de cyberharcèlement et cyberintimidation intraçable. Les agresseurs redoublent d’ingéniosité pour contrecarrer les règles de modération
- Il est de plus en plus facile de « stalker » une personne afin de récolter des informations pour lui nuire. On appelle ça le « doxxing »
- Les agressions se déroulent en majorité dans le jeu, et laisse de moins en moins de traces à l’écrit
- L’écran donne l’impression aux agresseurs, que leurs actions n’ont pas de conséquences
- Ce sentiment d’impunité est d’autant plus renforcé par le manque de volonté de modération et/ou de moyen de modération, sur les plateformes de discussion
#5 Les mondes imaginaires restent des créations humaines, avec des biais bien humains
L’un des éléments qui « permettent » (avec de GROS guillemets) aussi les agressions, c’est la narration des jeu, associée aux représentations qu’évoquent certains personnages.
Même si les mondes sont imaginaires, ils peuvent parfois répliquer :
- Des rapports de dominants-dominés ;
- Des rapports abusifs ;
- Des situations qu’il faut résoudre par la violence ;
- De la fétichisation et/ou sexualisation des corps.
On va éviter les raccourcis type « Les jeux vidéo rendent violents ». L’idée ici est de rappeler qu’en fonction de nos biais, et de nos vécus, certaines représentations, certaines histoires, entretiennent la violence des agresseurs, et leur sentiment d’impunité.
Nous faisons plutôt face à une double problématique, liée à des sujets plus sociétaux :
- Le manque de sensibilisation contre le harcèlement et ses conséquences
- Le manque de sanction et de médiatisation des sanctions face à ces comportements
#6 Le soucis de la performance
Autre motif, qui poussent certaines personnes à polluer l’expérience de jeu, c’est leur rapport à la performance de jeu.
Pour les jeux narratifs, l’objectif est d’entretenir une histoire
Pour ces types de jeu-là, on peut davantage jouer en ligne, dans un cadre bienveillant, car on n’a peu, voire pas, d’interaction avec d’autres personnes.
Pour les jeux de gestion ou de création, l’objectif est de créer puis de gérer un monde
En fonction des joueur•ses, les premières agressions viennent parce qu’on n’est pas d’accord sur la manière de faire ; pour saboter les choix du groupe ; ou venir d’une frustration de ne pas être en mesure d’avoir un monde aussi « stylé » que les autres.
Pour les jeux d’affrontement, l’objectif est d’être le n°1
C’est là qu’on retrouve le plus de « toxicité » liée à la performance
- On reproche aux autres sa défaite, ou celle de son équipe
- Pour les plus intolérants, on estime qu’il n’y a que les hommes cisgenres, qui soient capables d’être performants
- Pour les plus frustrés, on y estime que les personnes marginalisées qui performent, prennent la place des joueurs « qui étaient là avant »
- Pour les plus incohérents, on décrète que les personnes marginalisées perturbent la performance…par leur existence
#7 Les safe place, on les crée
Malheureusement et heureusement, les safe place sont des espaces qui se créent par les personnes concernées.
Ce qui est cool
- On peut y être soi-même
- Il y a moins de toxicité
- Il y a davantage de soutien et d’entraide
- L’expérience de jeu est peu perturbée
- La modération est réelle et plus efficace
Ce qui est moins cool
- Le problème des haters et des mauvais trolls n’est toujours pas résolu
- Les plateformes ne sont pas assez responsabilisées sur les sujets de modération, ni de sensibilisation
- Pour les débutant•e•s, les espaces bienveillants ne sont pas accessibles tout de suite
- Ce sont les victimes qui ont la charge de se protéger

Cybersécurité : à quoi sert un exercice de crise ?
Quand on pense à exercice de crise, comme beaucoup de sujet de cybersécurité, on a tendance à se dire qu’on n’est pas concerné, que c’est un projet lourd à mettre en place, ou qu’on se posera la question le jour où cela arrivera.
Nous savons aussi que l’approche par le risque est une approche lourde pour bon nombre d’organisation, parce qu’elle peut être rapidement anxiogène.
Et pourtant ! Rien de mieux que la mise en situation pour comprendre les enjeux de sécurité ! Et ce, pour plusieurs raisons :
- Cela permet de se poser les bonnes questions ;
- Cela implique toute l’entreprise ;
- Cela permet de visualiser concrètement ce qu’on fait de bien et ce qu’on peut améliorer.
On va vous éviter les expressions bateaux, type « il vaut mieux prévenir que guérir », mais globalement, en sécurité informatique, les coûts du manque d’anticipation ou de sensibilisation peuvent être très importants pour votre entreprise, quelle que soit sa taille.
Alors, dans quel contexte faut-il organiser un exercice de crise ? Sous quelle forme ? Avec qui ? Erwan Moyon vous fait part de son retour expérience, en tant qu’Ingénieur SI, anciennement Consultant en Sécurité des Systèmes d’information.
#1 — Qu’est-ce qu’un exercice de crise en cybersécurité ?
Un exercice de crise est une mise en scène, comme un jeu qui intègre différents acteurs d'une entreprise. Il se veut ludique et accessible.
Son objectif est de tester des situations de crise propre à l’entreprise pour mettre en avant des points d’amélioration, de sensibiliser et former les équipes à ce type d’évènements rares.
Dans le cadre de la cybersécurité, il s’agit d’organiser une mise en situation de cyberattaque ou de cyberincident.
#2 — Dans quel cadre doit-on organiser un exercice de crise ?
Il y a différentes situations qui peuvent justifier l’intérêt d’organiser des exercices de crises :
- Lorsque l’entreprise devient publiquement connue, cela attire les hackers et personnes malveillantes ;
- Lorsque l’entreprise a été hackée et a besoin de s’entraîner dans sa gestion de crise ;
- Lorsque l’entreprise s’apprête à lever beaucoup d’argents, ou dans le cadre d’une fusion-acquisition qui viendrait à modifier l’organisation de l’entreprise
#3 — Est-ce qu’il faut obligatoirement des spécialistes de la cybersécurité pour le faire ?
Les spécialistes sont les garants du suivi et de l’application des procédures de réponses à une crise. Ce n’est pas obligatoire, mais cela reste préférable pour :
- Conseiller la direction ;
- Définir des scénarii basés sur les tendances des cyberattaquants ;
- Investiguer et analyser les incidents qu’on va mettre en scène ;
- Accompagner les équipes IT et métier pour faciliter la communication et la remontée d’information ;
- Analyser les résultats de l’exercice et définir les plans d’amélioration et de sensibilisation
#4 — Quel type d’exercice de crise peut-on organiser ?
Il existe deux types d’exercice de crise : L’exercice sur table et l’exercice en réel.
Leur mise en place diffère en fonction des moyens de l’entreprise et de ses objectifs.
L’exercice sur table consiste à définir un scénario de crise propre à l’entreprise et de suivre une chronologie d’évènements. Ces évènements sont définis sur papier (ou PowerPoint).
Tous les participant•e•s vont devoir répondre à chaque évènement comme s’il était réel.
L’avantage de ce type d’exercice est qu’il est rapide à mettre en place et à simuler car il ne nécessite pas d’utiliser le système d’information.
L’exercice en réel est une mise en situation réelle. Par exemple, on peut installer un vrai sur une copie du système d’information. On va ensuite analyser en temps réel l’évolution du virus, ses impacts, les moyens à déployer pour le mitiger, la réaction des équipes etc.
L’avantage de ce type d’exercice est qu’il permet de tester le fonctionnement des logiciels de sécurité et d’analyser l’organisation de l’entreprise face à une cyberattaque.
En revanche, il nécessite un temps de préparation conséquent.
#5 — C’est quoi le déroulé classique d’un exercice de crise ?
Un exercice de crise s’organise en plusieurs temps.
Il faut d’abord cadrer et définir des scénarii de crise : que souhaite-t-on évaluer ? Quel est l’objectif de l’exercice de crise ? De quel type d’intervenants a-t-on besoin ? Quels sont les moyens IT qu’on peut mobiliser ? Qui est disponible pour y participer ? En moyenne, il faut bien 1 à 2 mois de préparation
Ensuite, il faut mobiliser les équipes, sur des temps où elles sont réellement disponibles. Il ne faut pas oublier qu’un exercice, c’est comme un jeu de rôle ou une simulation, il faut vraiment être impliqué dedans pour cela fonctionne. Si les équipes ont d’autres priorités ou si elles sont prises de court, l’exercice va les contraindre plus que les sensibiliser.
Pour les mobiliser, il est essentiel de prendre le temps d’expliquer régulièrement l’objectif de l’exercice, mais surtout de présenter les bénéfices que cela peut avoir. Pour cela, il faut aussi prévoir un plan de communication interne, au moins 1 mois à l’avance, avec des rappels. Quitte à mettre en place une permanence, pour répondre aux questions des participants.
L’exercice en lui-même dure de 1 à 3 jours, en fonction des scénarii choisis.
À la fin de l’exercice, on réalise un bilan à chaud, comme à la fin d’une formation. On organise également une enquête quelques temps après l’exercice. Cette enquête permet de comprendre comment l’exercice a été vécu, évaluer le niveau de compréhension, évaluer la culture sécu de l’entreprise en cas de crise…
Enfin, on réalise également un bilan global, à froid, qui comprend les points d’amélioration, mais aussi les bonnes pratiques à maintenir. Ce bilan est censé être décliné en plan d’action.
#6 — Comment faut-il communiquer un exercice de crise ?
La communication est très importante lors de l’organisation d’un exercice de crise
Les personnes mobilisées ne sont pas nécessairement très sensibilisées à ce qu’est un exercice de crise, notamment sur des sujets informatiques. Elles connaissent les risques de leur activité, mais n’y pensent pas tous les jours.
Il faut favoriser une communication en plusieurs temps également, avant, pendant et après. On peut évoquer les enjeux de l’exercice, réfléchir à des messages ludiques, d’autant plus qu’un exercice est assez ludique !
#7 — Qu’est-ce qu’on fait après avoir mis en place l’exercice ?
Après avoir réalisé un exercice il faut :
- Tirer un bilan des points positifs (ce qui a fonctionné) et les points d’amélioration (ce qui a moins bien fonctionné)
- Maintenir une certaine transparence sur les bilans, en évitant d’enjoliver les points d’amélioration ; le but de l’exercice c’est d’apprendre de nos erreurs courantes
- Définir un plan d’action cyber : mise à jour de procédures, renforcement de la communication, amélioration des outils…
- Le must du must, c’est de prévoir d’autres exercices pour s’améliorer continuellement jusqu’à qu’il y ait une vraie culture de la cybersécurité dans l’entreprise
#8 — C’est quoi les bénéfices concrets d’un exercice de crise ?
Concernant la cybersécurité, c’est une opportunité pour l’entreprise de :
- Identifier les points d’amélioration
- Comprendre les problèmes de communication interne et de sensibilisation à la sécurité
- Mettre en place des bonnes pratiques de cybersécurité, en fonction de chaque activité, de chaque outil utilisé
- Sensibiliser l’entreprise à la gestion de crise et instaurer une culture sécurité

Comment mettre en place une feuille de route pour un projet informatique ?
« Alors on en est où ? »
Cette question anodine suscite à la fois de l’enthousiasme (quand on a bien avancé) mais aussi beaucoup de frustration (quand on est en retard ou qu’on ne sait pas).
Pour arriver à y répondre sans stress, il y a un outil imparable, à la fois collaboratif et structurant : le feuille de route (ou roadmap).
Quelle que soit la forme que vous lui donnez, la feuille de route permet à tous les intervenant•es d’un projet informatique :
- Identifier les rôles et les relations entre chaque personne
- Comprendre les objectifs du projet
- Suivre les avancées et les communiquer
- Prioriser et réagir en cas de retard
C’est l’outil qu’il vous faut ? On vous explique en quelques étapes comment définir votre feuille de route IT.
#1 — C’est quoi une feuille de route concrètement ?
Une feuille de route, également appelée roadmap, est un document qui présente les principales étapes à suivre pour réaliser un projet. Ces étapes ont pour vocation d’être ensuite planifiées dans le temps.
Pour un projet informatique, à quelques spécificités près, le découpage est assez standard :
- Analyse de l’existant
- Conception
- Développement
- Test
- Déploiement
- Maintenance
#2 — Comment structurer une feuille de route ?
Une feuille de route se structure en trois grandes parties :
- Tout d’abords, vous définissez des « jalons », c’est-à-dire un ensemble de temps forts et/ou d’objectifs à atteindre
- Dans ces jalons, vous spécifiez des tâches à réaliser pour atteindre chaque objectif. En fonction des jalons, il y a peut-être un ensemble de tâches à rassembler en « chantier », qui constituent un « sous-jalon »
- Pour chaque tâche ou chantier, vous associez des personnes qui auront chacune des responsabilités dans la réalisation des tâches
- Ceci fait, vous inscrivez un niveau de priorité et des échéances pour chaque tâche ou chantier
- À l’issue de ce découpage, vous avez suffisamment d’éléments pour faire un planning
#3 — Quels sont les contenus les plus importants à suivre dans une feuille de route ?
Pour que votre feuille de route soit efficace, il y a plusieurs éléments importants à intégrer, et à valider régulièrement :
| À intégrer | À valider |
| Les charges temps | Combien de temps faut-il pour réaliser une tâche ? Ce temps a-t-il été respecté ? |
| Le budget | Combien a-t-on investi pour aboutir un jalon ?Combien a-t-on réellement dépensé ? |
| Les rôles et responsabilités | Les rôles sont-ils cohérents ? Les niveaux de responsabilité sont-ils clairs ? Les effectifs sont-ils suffisants ? |
C’est uniquement sur la base de ces éléments, qu’il est possible de définir une feuille de route claire, et suffisamment précise pour piloter un projet.
#4 — Comment mettre à jour une feuille de route ?
Nous mettons une feuille de route à jour dans les situations suivantes :
- Quand un chantier, une tâche ou un jalon est terminé
- Quand un risque vient impacter ou remettre en question la réalisation d’un chantier ou d’une tâche
- Quand une tâche a été mal estimée, ou qu’une nouvelle tâche doit être ajoutée et planifiée
#5 — Qui doit avoir la charge du suivi d’une feuille de route ?
Une feuille de route est gérée et pilotée par un•e chef•fe de projet, qui la met à jour en collaborant avec les différents intervenant•es du projet :
- Les équipes métiers ;
- Les services IT ;
- Les intervenant•es externes.
#6 — Quels sont les supports les plus pertinents pour mettre en forme une feuille de route ?
Il n’existe pas de supports prédominants pour définir une feuille de route, cela dépend des affinités du/de la responsable du projet, avec les outils qu’il/elle utilise habituellement.
En revanche, on peut identifier des usages spécifiques en fonction du support :
- Les outils de bureautique (type Suite Office) :
- EXCEL : Utiliser pour définir le planning et organiser les chantiers du projet
- PowerPoint : Utiliser pour communiquer les avancées et réaliser le reporting lié à la feuille de route
- Sharepoint : Utiliser pour communiquer les avancées de manière plus ludique et visuelle, pour associer des documents
- Les outils de gestion de backlog type JIRA ou Trello : Outil tout-en-un, très orienté développement informatique, pour planifier et définir les chantiers d’un projet en même temps
- Les outils de planning type Planner ou Monday : Outil collaboratif, plutôt orienté processus, qui permet à la fois de planifier et de donner une vue d’ensemble au projet
Une fois structurée, les rôles clarifiés et les différentes charges du projet définies, le suivi d’une feuille de route offre plusieurs bénéfices :
- Fluidifier la communication : Une feuille de route est facile à lire ce qui permet de rapidement communiquer sur ses avancées, blocages, etc. auprès de n’importe quel interlocuteur d’un projet
- Renforcer la collaboration : Ce document unique et central permet de renforcer les échanges et le travail entre les équipes IT et les équipes métiers
- Faciliter la prise de décision : Une feuille de route permet de rapidement mettre en avant des risques capacitaires, financiers ou les conflits de planning, afin de prendre des décisions
- Prioriser les chantiers : Une feuille de route permet rapidement d’identifier et de définir des priorités vis-à-vis des jalons importants, de leur complexité de réalisation et des délais de livraison
Prêt à mettre en pratique nos conseils ?
Voici un outil signé Cool Kit pour vous exercer à définir votre feuille de route informatique
➡️ https://coolkit.coolitagency.fr/toolspage/details/14 ⬅️
Besoin d’aide ?
Chez Cool IT, nous avons développé nos propres méthodes, largement éprouvées (depuis plus de dix ans !), pour vous aider à mener à bien vos projets informatiques.

Pourquoi mettre en place une politique de gestion de mots de passe ?
“123456”, “qwerty”, “password”, “marseille”, “loulou”… En 2021, les pires mots passe sont toujours les mêmes. On estime même que 406 millions mots de passe ont été divulgués en 2021, soit une moyenne de 6 mots de passe par habitant (source NordPass).
En moyenne, il faut moins d’une seconde pour hacker un compte personnel, qui utilise un mot de passe trop simple. Pour une entreprise dont la gestion des mots de passe est faiblement sécurisée, le risque est le même.
Dans cet article, nous allons vous donner quelques pratiques fondamentales pour mettre en place une politique de gestion de mots de passe.
#1 — Définir un mot de passe complexe
Tout commence avec le bon choix du mot du passe ! Choisir un mot de passe sécurisé permet de :
- Réduire les risques qu’une personne malveillante accède à un compte utilisateur de l’entreprise ;
- Renforcer la sécurité des comptes administrateurs ;
- Intégrer la sécurité dans les bonnes pratiques professionnelles des collaborateurs.
Il y a plusieurs critères à intégrer dans son mot de passe, afin de garantir un niveau de sécurité suffisant :
- 12 caractères minimum ;
- Au moins 1 majuscule ;
- Au moins 1 minuscule ;
- 1 chiffre et un caractère spécial.
On vous l’accorde, il est difficile de retenir et d’innover constamment ce type de mot de passe. Pour cela, le plus simple reste d’utiliser un générateur de mot de passe, comme le générateur en ligne motdepasse.xyz ou les générateurs de logiciel de sécurité en ligne tels que Dashlane, 1password ou Avast.

#2 — Éviter la réutilisation de mot de passe
Même si le mot de passe est complexe, s’il vient à être compromis et divulgué sur internet, il devient inutilisable.
Les hackers utilisent des programmes pour automatiser leurs attaques et trouver les mots de passe.
Dès qu’ils ont en trouvé un, ils le réutilisent sur d’autres sites internet, et ainsi de suite. Les mots de passe volés sont soit revendus, soit utilisé pour compromettre les données de l’entreprise.
Il faut donc éviter au maximum la réutilisation de mots de passe, même avec quelques variantes, comme : « loulou22 », « loulou23 » … Les hackers anticipent également les variations possibles.
#3 — Utiliser un coffre-fort numérique
Avec la multiplication des outils en ligne, nous avons forcément une multiplication de mots de passe. Cette multiplication de mots de passe peut parfois mener à des failles dans la politique de mot de passe, ou l’utilisation de mémo matériel, très risqué : tableau Excel, post-it…
L’utilisation d’un coffre-fort numérique peut permettre de :
- Stocker l’ensemble des mots de passe sur un serveur sécurisé ;
- Générer aléatoirement des mots de passe complexes ;
- Se connecter sans avoir à saisir les identifiants et mots de passe ;
- Partager des données sensibles de manières sécurisées.
Le coffre-fort est protégé par un seul mot de passe maître à retenir. La perte ou la compromission de cet unique mot de passe peut être prise en charge par l’éditeur qui vous propose le coffre-fort.
Parmi les plus connus du marché, on retrouve : Dashlane, NordPass, KeePass, LastPass...

#5 – Éviter de passer par des systèmes tiers, non-dédiés à la sécurité
Google, Facebook, Twitter, LinkedIn… proposent tous des moyens de s’authentifier via leur propre système d’authentification. Le problème avec des services tiers, c’est la dépendance. Si ces derniers viennent à être attaqués, il y a un risque à ce que les accès de l’entreprise soient compromis.
Il en va de même pour les navigateurs : Chrome, Firefox, Edge etc. Ces services sont régulièrement attaqués, et comportent régulièrement des failles de sécurité.
Pour les sujets de sécurité, comme les mots de passe, il vaut mieux privilégier des services dédiés à la sécurité (générateurs, coffre-fort…)
#5 – Activer la double authentification
On ne le répète jamais assez ! Le risque zéro n’existe pas ! On œuvre surtout à réduire les risques au maximum. Les pratiques citées ci-dessus permettent de réduire les risques de vol de mot de passe, mais ne l’empêche pas 100%
Pour renforcer la sécurité d’accès à un compte, il est également conseillé d’en renforcer l’accès via la double authentification.
Cette méthode de sécurité permet, au moment de la connexion à son compte, d’utiliser un second moyen d’authentification pour accéder à son compte. On vérifie doublement la personne qui devra se connecter via un SMS, un e-mail, une application en plus.
Les bénéfices de la double authentification sont multiples :
- Renforcer la sécurité des accès aux comptes sensibles de l’entreprise ;
- Empêcher l’accès à un compte même si le mot de passe a été volé ;
- Renforcer la sécurité en dehors du bureau.
Les méthodes de cyber hacking de mots de passe continuent de se perfectionner, au fil des années. Les attaques sont de plus en plus subtiles. Par exemple, on sait qu’aujourd’hui les hackers peuvent tenter de contrepasser la double authentification.
Pour réduire les risques de sécurité, les entreprises doivent impérativement s’armer d’une politique de gestion de mots passe robustes :
- Définir des mots de passes complexe ;
- Privilégier les coffres forts numériques ;
- Éviter les solutions tierces ;
- Sensibiliser les collaborateurs à la réutilisation ;
- Mettre en place la double authentification.
En complément de ces pratiques, on peut ajouter le renouvellement des mots de passe tous les 90 jours, afin de toujours garder un temps d’avance sur les attaques possibles. Sans oublier, de sensibiliser régulièrement les collaborateurs sur les différents risques et actualités cyber liés aux mots de passe.

Comment sécuriser son entreprise avec des logiciels Open Source ?
Chaque année, 370.000 logiciels Open Source sont téléchargés dans le monde. Le dernier rapport de Sonatype, appelé « State of the Software Supply Chain 2020 » a même identifié que 29% de ces logiciels possédaient des vulnérabilités, soit un tiers du marché actuel de l’Open Source. En 2021, le nombre d’attaques utilisant des vulnérabilités Open Source a augmenté de 650%
La plus importante et dernière en date concerne l’exploitation d’une vulnérabilité appelée Log4Shell. Cette vulnérabilité a été détectée dans le logiciel Log4Js, lui-même utilisé par le logiciel Apache, solution utilisée par des dizaines de milliers de site web.
Cet évènement a remis au centre des préoccupations les conditions d’utilisation des logiciels Open Source, les pratiques de maintenance et de financement.
#1 — Open Source, de quoi parle-t-on ?
Un logiciel Open Source, ou logiciel libre, est un programme informatique dont le code est publiquement accessible. N’importe qui peut y accéder, le modifier et en distribuer le code. L’Open Source existe depuis que l’informatique existe.
Le modèle de développement d’un logiciel Open Source est différent d’un logiciel propriétaire :
- Il se repose sur le travail bénévole de communautés de développpeur·ses, à maintenir le code du logiciel sans demander de contrepartie financière
- Il s’enrichit de manière collaborative, n’importe qui, tant qu’iel en a les compétences peut contribuer à améliorer le code
- Il est censé entièrement responsabiliser les utilisateur·rices, qui peuvent eux-mêmes l’exploiter comme iels le souhaitent
La fiabilité d’un logiciel Open Source est donc fortement associée aux développeur·ses qui le maintiennent. Les solutions les plus fiables, comme celles de Red Hat (1er éditeur mondial de solutions Open Source), sont gratuits pour les utilisateur·rices les plus débrouillard·es, payants pour celles et ceux qui souhaitent bénéficier d’un service similaire à une version propriétaire.
En dehors de ce modèle, la gratuité totale peut amener à des problématiques de mise à jour, sécurité, de performance, d’ergonomie…
#2 — Que renforce les dernières cyber actus des problématiques du Logiciel Libre ?
Depuis Log4Shell, on réalise que les risques cyber, qui ciblent les failles de l'Open Source, peuvent être subtiles mais ne sont pas inédites. Tels que l’exploitation de codes vulnérables, le sabotage de logiciels, le découragement des développeur·ses…
Les raisons sont diverses :
- Peu ou pas d’audit interne en amont ;
- Peu ou pas de vérification de la qualité du code ;
- Surcharge de travail des développeur·ses Open Source ;
- Maintenance peu réalisée après la mise en production …
90% des programmes informatiques existants utiliseraient des modules Open Source pour fonctionner. Cela sous-entend que la majorité des programmes du marché sont dépendants de leur fiabilité.
Du fait de cette dépendance, il y a un réel enjeu à valoriser l'Open Source d’une part, et d’autre part à renforcer les politiques de maintenance.
3 — Pourquoi financer les développements Open Source ?
Le développement Open Source n’est pas gratuit pour ses créateur·rices. Il demande du temps, souvent pris sur le temps libre de développeur·ses passionné·es. Pour en tirer profit, il est primordial de valoriser les communautés qui font vivre ce milieu, afin qu’iels aient les moyens de proposer des solutions plus fiables.
Les modèles de rémunération peuvent être divers :
- Recruter un·e développeur·se et/ou un expert en interne pour travailler sur la maintenance ;
- Rémunérer directement les développeur·ses Open Source, si iels proposent des services de maintenance ;
- Financer des programmes Open Source : collectifs, formation, entreprise spécialisée, initiatives gouvernementales...
Néanmoins, il faut garder en tête que l’Open Source ne fonctionne pas pour tout. Cela requiert un véritable questionnement sur la dépendance informatique et sur sa propre politique de maintenance, de sécurité.
4 — Mais du coup, doit-on arrêter d'exploiter les logiciels Open Source ?
Non ! L’Open Source contribue à l’enrichissement de l’informatique.
Il permet :
- d’accélérer l’innovation
- de maintenir l’accessibilité logiciel aux organisations plus modestes
- d’expérimenter des produits
Ce n’est pas le modèle d’organisation qui est à revoir, mais l’exploitation des logiciels.
Pour citer Sylvain Abélard, ingénieur logiciel chez Faveod : « Le soucis n’est pas les gratuit, c’est de mal exploiter le gratuit. »
Pour une meilleure exploitation des logiciels libres, il faut donc :
- Être en mesure de se responsabiliser, calibrer leur dépendance et investir davantage sur la maintenance, la sécurité
- Soit fournir des contreparties justes aux acteur·rices de l’Open Source
Ainsi, les organisations pourraient être en mesure d’entretenir un cercle vertueux. La traçabilité des développements contribueraient à la fois au maintien des valeurs de l’Open Source, mais aussi au maintien des organisations de ses exploitants.

Flex office : les étapes à ne pas manquer côté informatique
Le Flex Office consiste à proposer un espace de travail où les bureaux ne sont pas attitrés.
Renforcé par l'évolution du travail hybride, le Flex office permet à l’entreprise de réduire ses coûts immobiliers, tout en proposant aux salarié-e-s des conditions de travail, elles aussi flexibles.
Il permet également de répondre à un besoin croissant des salarié-e-s de pouvoir travailler dans des conditions différentes, selon son organisation et ses tâches quotidiennes, elle dynamise également les échanges entre collègues.
D’un point de vue informatique, un plan d’action est nécessaire pour détailler l’ensemble des tâches attendues pour assurer une mise en place efficace, et faciliter au maximum l’accès aux outils de travail.
Ces différentes actions impliquent différents acteurs IT :
- Un-e chef de projet IT en charge de la coordination du projet, du planning, de l’analyse des coûts d’investissement et de l’organisation du déploiement
- Un-e responsable IT en charge de réaliser les inventaires logiciels et matériels
- Un-e responsable de la conduite du changement en charge à la fois de la communication avec les salariés et managers, de l’identification des points de blocages et de réticences, et de l’accompagnement au changement des services métiers et IT
- Un-e responsable des services généraux pour l’organisation de l’espace de travail
Le service IT est garant de la réalisation et de l’accompagnement des équipes dans la mise en place du flex office.
Les services métiers seront, quant à eux, régulièrement consultés durant la réalisation de ces actions.
#1 — Réaliser un inventaire du matériel informatique
La première étape à suivre, avant de lancer la mise en place du flex office, consiste à réaliser un inventaire du matériel informatique de l’entreprise et d’identifier le nombre de :
- Ordinateurs fixes et portables
- Appareils téléphoniques (smartphones et téléphones fixes)
- Bornes WIFI
- Decks et câbles de chargement d’ordinateurs
- Écrans d’ordinateurs
Il faut ensuite valider la mise à disposition pour chaque salarié-e d’un moyen de rangement sécurisé de leurs affaires. Les postes n’étant plus attribués, les salarié-e-s ont besoin de déposer leurs matériels et effets personnels dans un endroit qui leur est propre. Il faut prévoir pour chacun un casier sécurisé et de quoi transporter son matériel facilement.
#2 — Référencer les logiciels informatiques
Les logiciels informatique et systèmes de stockages de fichiers sont à inventorier pour identifier les manques et assurer la continuité d'activité des salarié-e-s.
Pour cela, il faut :
- Lister les solutions informatiques utilisées
- Identifier pour chaque logiciel, s’il est accessible à distance via une connexion internet
- Prévoir de faire évoluer ou de changer les logiciels qui ne permettent pas de travailler à distance
- Stocker les données sur un disque dur et/ou serveur externe géré par un infogérant, ou sur une solution cloud telles que Google Cloud Storage, OneDrive, Dropbox, IBM Cloud Storage…
#3 – Organiser l’espace de travail
Pour organiser l’espace, il faut dans un premier temps valider le nombre de postes « flex office » qui sera mis à disposition.
A l’issu de cette identification, il faut :
- Quantifier le nombre d’écrans par poste
- S’assurer de la mise à disposition d’un moyen de chargement de l’ordinateur
- Vérifier la qualité du réseau WIFI
L’espace de travail en mode flex office doit comprendre des espaces de réunion et des salles d’appel Même en flex office, les équipes maintiennent le besoin d’avoir des temps collectifs en réunion et des temps d’appel en espace individuel.
Il est également conseillé de prévoir un système de visioconférence performant pour le travail hybride (CISCO, Teams, OneDirect, Zoom…) qui permette aux salariés de maintenir la cohésion d’équipe, même dispersée. Attention cependant à l’effet réunionite ! Les visio doivent être plus brèves et plus cadrées pour rester pertinentes pour les salarié-e-s présents et à distance.
#4 – Identifier le coût d’investissement à réaliser
A l’issue de l’analyse et de la réalisation des précédents points, il est possible d’identifier le coût d’investissement pour la mise en place du flex office.
D’un point de vue matériel et réseau :
- Identifier les écrans et autres matériels manquants à acheter ou à remplacer
- Identifier les besoins d’investissement dans des solutions réseaux (bornes WIFI, changement d’opérateurs, renforcement de la fibre…)
Si l’entreprise utilise des téléphones fixes, le salarié-e doit pouvoir maintenir sa propre ligne privée. Pour cela il existe deux types de solutions :
- Passer sur des solutions de téléphonie VoIP (via TrunkSIP ou autres solutions)
- Passer sur des solutions de téléphonie SaaS qui redirigent les appels vers le poste utilisateur
Attention cependant, à bien encadrer et respecter les temps de disponibilités de chacun.
En cas d’usage d’ordinateurs fixes, il faudra soit envisager d’investir dans des solutions de virtualisation de postes de travail (VMware, Compufirst, Windows Virtual Desktop…) ou de remplacer le matériel par un ordinateur portable.
Concernant les logiciels, le changement de logiciels implique de :
- Valider les logiciels devant être remplacés
- Réaliser un benchmark pour valider les nouveaux logiciels
- Potentiellement investir dans une prestation de service, si l’équipe IT est surchargée ou en sous-effectif
- Décommissionner les anciens logiciels (arrêt et finalisation des contrats)
#5 – Déployer le Flex Office
A partir du moment où les inventaires sont réalisés, le coût d’investissement défini et que le mode d’organisation des équipes est identifié, la mise en place technique du flex office peut débuter.
Pour cela, il faut :
- Procéder à l’achat du matériel manquant
- Installer les nouveaux logiciels et migrer les systèmes informatiques
- Renforcer la communication auprès des équipes avec le partage d’un retroplanning, une communication et des échanges réguliers
- Organiser une semaine de tests sur les postes dédiés
- Prévoir un jour de télétravail le jour de la bascule
#6 – Accompagner au changement
L’accompagnement au changement débute dès le début de la mise en place du flex office, à savoir :
- Préparer une communication sur ce qu’est le flex office, ses impacts, avantages et ce que cela implique en termes de changement ;
- Identifier avec chaque manager l’impact organisationnel que cela va avoir ;
- Identifier les irritants et les contraintes ;
- Renforcer la communication interne de manière positive : apports dans les relations professionnelles, retours d’expériences, étude de situation… ;
- Planifier des temps d’échanges pour évaluer le bon déroulé du flex office : points d’attention, axes d’amélioration, état du matériel, état de la cohésion d’équipe…
Quel que soit la taille de l’entreprise, le flex office est un mode d’organisation qui nécessite un plan d’action concret, qui implique :
- Un inventaire du matériel ;
- Un référentiel des logiciels ;
- Une évolution des méthodes de management ;
- Des investissements immédiats ;
- Un plan de conduite du changement ;
- Une politique d’amélioration continue des conditions de travail.
Le retour sur investissement peut être rapide et permet à l’entreprise de revoir ses méthodes de management. Elle permet également à l’entreprise d’accélérer sa transformation digitale, de gagner en agilité dans la gestion de son Système d’Information.
Cela permet de mélanger des corps de métier qui discutent peu en temps normal.
Pour les équipes IT, c’est l’opportunité de valoriser davantage le rôle que les équipes jouent dans l’organisation du travail et ses mutations.
Besoin de renfort pour mettre en place du Flex office ?
Vous pouvez écrire à Erwan, l'auteur de l'article
Besoin d'un modèle plus visuel pour organiser votre mode Flex office ?
Découvrez notre modèle Trello